자연어를 분석하여 텍스트의 property, value, visuals 등의 정보를 Unit visualization을 기반으로 쉽게 애니메이션을 만들 수 있게 하는 DataParticles 라는 툴에 대한 연구입니다.
읽은 날짜 2023.03.24
카테고리 #시각화논문리뷰, #DataVisualization, #UnitVisualization, #DataStorytelling
DataParticles: Block-based and Language-oriented Authoring of_Animated Unit Visualizations
- Authors: Yining Cao, Jane L.E, Zhutian Chen, Haijun Xia
- DOI: https://creativity.ucsd.edu/papers/dataparticles.pdf
- Keywords: unit visualization, natural language, animation, storytelling
- Issue Date: 2023
- Publisher: CHI'23: Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems

ABSTRACT
배경 및 문제점: Unit visualization은 interactive article이나 video에서 데이터 스토리텔링에 널리 사용된다. 하지만 Unit visualization이 포함된 데이터 데이터 스토리를 작성하는 것은 매우 까다롭고 시간이 소모된다.
목표: Unit visualization 프로세스 간소화를 위해, 텍스트, 데이터, 시각화 사이의 연결을 활용하여 제작자가 유연하게 스토리 탐색 및 프로토타이핑을 하도록 하는 툴 'DataParticles' 개발.
DataParticles - a block-based story editor that leverages the latent connections between text, data, and visualizations to help creators flexibly prototype, explore, and iterate on a story narrative and its corresponding visualizations.
방법: 6명의 도메인 전문가를 인터뷰하고, 44개의 현존하는 unit visualizations 데이터 셋을 연구하여 내러티브 패턴(narrative pattern)과 congruence principles를 파악하고, 니즈에 맞는 툴을 개발하였다.
평가: 9명의 전문가를 대상으로 user study를 진행
결과: DataParticles는 데이터 탐색과 빠른 프로토타이핑을 지원하여, Unit visualization의 애니메이션을 사용한 데이터 스토리 작성 프로세스를 매우 단순화할 수 있다.
1. INTRODUCTION
■ Unit visualization의 장점
- aggregate visualization과 달리, visual marks와 data points간에 1:1 매핑을 통해, 다양하고 의미를 담은 애니메이션을 제공한다.
정보를 작은 덩어리로 전달하여 viewer에게 최종 메시지로 원활하게 안내한다.
■ Unit visualizatino 단점
- 만들기가 어렵고, 지겹고, 시간을 소모하는 작업이다.
- storytelling을 위해서는 콘텐츠가 의미론적, 시간적으로 일치해야 하는데, 이를 위한 툴이 없다. (크리에이터가 직접 여러 툴을 왔다 갔다 해야 함.)
■ 연구 목표
- AUV (Animation Unit Visualization)를 사용하는 data story를 생성하는 과정에서의 문제를 탐색하고, 프로세스를 간소화하는 것.
■ 평가
- 6명의 AUV 크리에이터를 대상으로 한 Formation study 진행했음.
■ 이 연구의 기여 내용
- (1) 전문 크리에이터를 대상으로 한 formative study를 통해, AUV를 사용해 data-driven stories를 창작할 때의 common workflow와 pain points를 식별함.
- (2) 서사 구조의 공통 패턴과 텍스트와 시각적 요소 사이에 존재하는 매핑을 식별하는 AUV를 사용한 44개 스토리의 콘텐츠 분석.
- (3) DataParticles 프로토타이핑 시스템은 텍스트와 시각적인 매핑을 활용하여, AUV가 포함된 데이터 스토리 작업 시, language-driven 하고, 블록 기반의(blockbased) 제작 경험으로 만든다.
- (4) 전문가 평가를 통해 DataParticles의 유용성을 확인받고, 미래의 디자인 프로토타이핑과 language-oriented authoring tools에 대한 인사이트 있는 design implications를 보여준다.
■ 이 연구는 AUV로 데이터 스토리 생성을 지원하는 데 중점을 두고 있지만 제안된 사용자 인터페이스 및 상호 작용 기술을 다른 유형의 데이터 시각화(예: 집계 차트)에 적용할 수 있다.
■ 이 논문에서는
DataParticle툴의 구상 배경 및 창작 과정과 사용 방법 설명 및 예시를 다룬다.
2. RELATED WORK
아래의 네 가지 선행 연구를 기반으로 한다.
- Unit visualization
- Data storytelling
- Natural language-oriented interactions
- Block-based interfaces for content creation
2.1 Unit visualization
■ Unit 또는 glyph-based 시각화
- 인포그래픽, data-driven 애니메이션, AR visualizations, data physicalizations과 같은 범위의 시나리오에서 communicating data의 매체로서 점점 더 유명해지고 있음.
- 관련 선행 연구 - tools, frameworks, design spaces
■ Design space
(1) Unit visualization을 위한 design space를 정의하고, unifying framework 제안
> Steven Drucker and Roland Fernandez. 2015.
> A unifying framework for animated and interactive unit visualizations. Microsoft Research (2015)
(2) Unit visualization을 표현하는 문법. 추후 이 문법이 SandDance 개발에 사용됨.
> Deokgun Park, Steven Mark Drucker, Roland Fernandez, and Niklas Elmqvist.
> Atom: A Grammar for Unit Visualizations. IEEE Trans. Vis. Comput. Graph. 24, 12 (2018), 3032–3043.
> https://doi.org/10.1109/TVCG.2017.2785807
■ Tools
Unit visualization 생성을 위한 도구들이 개발되었으나, Unit visualization에서 애니메이션을 생성하는 것은 여전히 어려운 과제.
(1) 'Data animator' 툴 (SOTA data animation system)
keyframing과 정적인 시각화 사이를 interpolating 하는 방법으로 animated data visualizations 생성.
> John R. Thompson, Zhicheng Liu, and John T. Stasko. 2021.
> Data Animator: Authoring Expressive Animated Data Graphics. In CHI ’21: CHI Conference on Human Factors in Computing Systems, Virtual Event / Yokohama, Japan, May 8-13, 2021. ACM, 15:1–15:18.
> https://doi.org/10.1145/3411764.3445747
(2) data-facts를 나열하여 AUV 생성하는 연구
규칙 기반, 템플릿 기반 텍스트 디스크립션의 한계로 표현력이나 생성과정의 제어 가능성이 제한됨.
> Junhua Lu, Wei Chen, Hui Ye, Jie Wang, Honghui Mei, Yuhui Gu, Yingcai Wu, Xiaolong Luke Zhang, and Kwan-Liu Ma. 2021.
> Automatic Generation of Unit Visualization-based Scrollytelling for Impromptu Data Facts Delivery. In 14th IEEE Pacific Visualization Symposium, PacificVis 2021, Tianjin, China, April 19-21, 2021. IEEE, 21–30.
> https://doi.org/10.1109/PacificVis52677.2021.00011
2.3 NLI for Data visualization
■ NLI (Natural language interfaces)
- 자연어 쿼리, 대화 텍스트를 통한 인터랙티브 시각화 연구
- 자연어 분석에 대한 시각화 연구
- 텍스트와 데이터의 연결에 대한 연구
Voder: 데이터 이해와 탐색을 위한 인터랙티브 위젯 (자연어에서 data facts를 생성)
> Arjun Srinivasan, Steven M Drucker, Alex Endert, and John Stasko. 2018.
> Augmenting visualizations with interactive data facts to facilitate interpretation and communication. IEEE transactions on visualization and computer graphics 25, 1 (2018), 672–681.
DataTone: 자연어 쿼리로 aggregated visualizations을 만들고 인터랙티브 위젯을 제공.
> Tong Gao, Mira Dontcheva, Eytan Adar, Zhicheng Liu, and Karrie Karahalios. 2015.
> DataTone: Managing Ambiguity in Natural Language Interfaces for Data Visualization. In Proc. of UIST. ACM, 489–500.
> https://doi.org/10.1145/2807442.2807478
Eviza: 자연어의 구조를 활용해서 지속적으로 인터랙티브 한 대화를 통해 data visualizations를 생성하고 수정함.
> Vidya Setlur, Sarah E. Battersby, Melanie Tory, Rich Gossweiler, and Angel X.Chang. 2016.
> Eviza: A Natural Language Interface for Visual Analysis. In Proc. of UIST. ACM, 365–377.
> https://doi.org/10.1145/2984511.2984588
Orko:
> Arjun Srinivasan and John T. Stasko. 2018.
> Orko: Facilitating Multimodal Interaction for Visual Exploration and Analysis of Networks. IEEE Trans. Vis. Comput. Graph. 24, 1 (2018), 511–521.
> https://doi.org/10.1109/TVCG.2017.2745219
InChorus:
> Arjun Srinivasan, Bongshin Lee, Nathalie Henry Riche, Steven M. Drucker, and Ken Hinckley. 2020.
> InChorus: Designing Consistent Multimodal Interactions for Data Visualization on Tablet Devices. In Proc. of CHI. ACM, 1–13.
> https://doi.org/10.1145/3313831.3376782
NL4DV: 자연어 분석 과정을 시각화
- Query Parsing
- Attribute Inference
- Task Inference
- Visualization Generation
> Arpit Narechania, Arjun Srinivasan, and John Stasko. 2021.
> NL4DV: A Toolkit for Generating Analytic Specifications for Data Visualization from Natural Language Queries. IEEE TVCG 27, 2 (2021), 369–379.
> https://ieeexplore.ieee.org/document/9222342
자연어의 Utterances 데이터를 수집 및 분석한 연구
- Phrasing (e.g., commands, queries, questions)
- Information (5 types: attribute, chart types, encoding, aggregation, design)
> Arjun Srinivasan, Nikhila Nyapathy, and Bongshin Lee. 2021.
> Collecting and Characterizing Natural Language Uterances for Specifying Data Visualizations. In Proc. of CHI. ACM.
> https://doi.org/10.1145/3411764.3445400
ArkLang:
자연어 분석의 syntactic, semantic 한 제약이 있는 partial utterances를 해결
> Vidya Setlur, Melanie Tory, and Alex Djalali. 2019.
> Inferencing underspecified natural language utterances in visual analysis.
> In Proceedings of the 24th International Conference on Intelligent User Interfaces. 40–51.
> https://dl.acm.org/doi/10.1145/3301275.3302270
CrossData:
- 데이터와 텍스트의 연결을 유지하면서, 데이터 수정 시 텍스트에 인터랙티브 하게 반영됨.
> Zhutian Chen and Haijun Xia. 2022.
> CrossData: Leveraging Text-Data Connections for Authoring Data Documents.
> In CHI ’22: CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April 2022 - 5 May 2022. ACM, 95:1–95:15.
> https://doi.org/10.1145/3491102.3517485
Kori:
- 데이터가 있을 때, 차트는 graphical summaries를 제공하고, text는 컨텍스트와 메시지를 제공한다.
- 아티클을 읽을 때 유저는 데이터 차트와 텍스트 관계에서 계속 주의를 전환해야 하는 불편함이 있음.
- data documents에서 텍스트와 차트의 tight coupling을 위한 방법에 대한 연구.
- chart-text references에 대한 디자인스페이스 분석 및 mixed-initiative interface를 개발함.
> Shahid Latif, Zheng Zhou, Yoon Kim, Fabian Beck, and NamWook Kim. 2021.
> Kori: Interactive Synthesis of Text and Charts in Data Documents. IEEE Transactions on Visualization and Computer Graphics 28, 1 (2021), 184–194
> https://ieeexplore.ieee.org/document/9552930
■ 이 연구의 목표 - 아래의 내용을 지원하는 DataParticle툴을 구현한다.
- 스토리텔링 프로세스에서 시각적 요소와 자연어의 매핑
- Unit visualizations의 유연성을 활용하여, 내레이션과 일치하는 애니메이션 시각적 스토리를 생성
- 인터랙션 테크닉 지원
2.4 Block-based Editing for Data-driven Content Creation
→ 이 연구의 DataParticle이 편집 환경으로 '블록 기반 편집기 스타일(block-based editing paradigm)'을 차용하게 된 배경 연구 언급
Lau et al.,의 Computational Notebooks에 대한 Design Space 연구를 참고하여, 블록 기반 편집기 스타일을 채택.
- 60개의 s(- Jupyter, R Markdown, Observable)를 조사한 결과, 대부분 블록기반 편집기 스타일을 채택했음을 밝힘.
- computational notebooks를 위한 design space를 제안.
> Sam Lau, Ian Drosos, Julia M. Markel, and Philip J. Guo. 2020.
> The Design Space of Computational Notebooks: An Analysis of 60 Systems in Academia and Industry.
In IEEE Symposium on Visual Languages and Human-Centric Computing, VL/HCC 2020, Dunedin, New Zealand, August 10-14, 2020. IEEE, 1–11.
> https://doi.org/10.1109/VL/HCC50065.2020.9127201
3. FORMATIVE STUDY
- 연구 초기 관심사 - 복잡한 애니메이션을 포함한 data-driven 스토리의 창작 방법, 창작 과정에서 제작자의 챌린지
3.1 Interviewees and Procedure
6명의 도메인 전문가와 Semi-structured interview 진행
- 다른 유형의 animaed data stories 제작경험 5년 이상의 프로듀서, 애니메이터, 시각화엔지니어, 저널리스트 등.
3.2 Workflows While Creating AUVs
■ Workflows
(1) 제작을 가이드하기 위한 data stories의 narratives(내러티브)
(2) narrative planning을 기반으로 시각화와 애니메이션 창작.
low-fidelity prototype에서 high-fidelity design으로 발전
(3) 내러티브와 비주얼을 구성하여 완성된 스토리를 구성
■ Planing and prototyping phases에서의 두 가지 Approach
(1) data-driven planning
- 제작자는 토픽에 대하여 data-driven inquiry를 수행하고, 데이터 분석에서 발견한 인사이트를 전달하기 위한 영상을 제작.
- 복잡한 아이디어나 데이터를 쉬운 방식으로 전달하여, 정보의 이해와 기억을 돕기 위한 목적.
(2) story-driven planning (= narrative-based approach)
- 제작자는 데이터를 보여주기 위하여 내러티브를 작성하고 시퀀스를 결정.
- 스토리에 맞는 data facts를 검색하고, supporting evidence를 위해 시각화 통합
- 청중의 관심을 끌고 매력적이고 설득적인 방법으로 정보를 전달하는 내러티브를 만드는 것에 초점을 둔다.
3.3 Challenges Encountered by Creators
3.3.1 Difficulties and Downstream Frustrations While Planning and Prototyping AUVs
Static graphics이나 aggregated visualizations에 비해, AUV의 프로토타이핑은 까다롭고,
AUV의 final look까지 AUV가 내러티브를 일관되게 보여줄 수 있을지 예측하기 어렵다.
AUV를 다 만들고 나서야 처음으로 AUV결과물을 볼 수 있게 되므로, 작업 도중에 스토리텔링이 제대로 되고 있는지 알 수 없다는 불편함이 있다.
3.3.2 Tedious and Complex Workflows During AUV Creation
■ 인터뷰 참가자들이 응답한 AUV 작업 Workflow
(1) 먼저 데이터를 분석하기 위해 Excel과 같은 스프레드시트 애플리케이션이나 R, Python과 같은 프로그래밍 툴킷을 활용한다.
(2) 시각화 애니메이션을 만들기 위하여, 애니메이션을 직접 구현하는 툴보다는 d3.js와 같은 프로그래밍 라이브러리를 사용한다.
■ Pain point
- 디자인과 코드 구축을 위한 배경 지식 필요, 상당한 시간 소모
- 종종 'per data point' animations (예: highlighting, pulsing) 이 필요한 경우, 매우 지겨운 수동 작업이 요구된다.
- 참가자들은 video-based stories의 경우, 프로그래밍으로 만들기 힘든 애니메이션이나 final touches를 위해 Adobe AfterEffects와 애니메이션 전용 도구를 사용했다.
3.3.3 Repetitive Synchronization for Story-Visual Congruence
인터뷰 참가자들은 스토리와 비주얼을 매칭시키는 것이 효과적인 커뮤니케이션과 스토리텔링에 매우 종요하다고 했다.
3.4 Summary
■ The findings
- data points와 시각화 사이의 일대일 매핑을 통해 AUV의 내러티브에 힘을 싣을 수 있으나, 이 점은 AUV를 계획하고 탐색하고 프로토타이핑하는 것을 어렵게 한다.
- the authoring process가 다양한 툴/환경에 분산되어 사용되기 때문에, 스토리와 데이터, 비주얼의 linkage(연결)을 유지하기 어렵다.
→ data stories 크리에이터는 특히 planning stage의 초기 단계에서 flexible prototyping과 구조화된 스캐폴딩을 통해 이점을 얻을 수 있다.
4. CONTENT ANALYSIS OF DATA STORIES CONTAINING AUVS

4.1 Narrative and Organization Structures
→ 서로 다른 형식에도 불구하고 data-driven article과 videos는 유사한 내러티브 및 콘텐츠 조직 구조를 사용한다. (Figure 2a)
4.1.1 Inverted Pyramid Narrative Structure
가장 많은 내러티브(서사 구조) 형태 : 역 피라미드 구조
high-level context (범위, 배경, 핵심메시지)로 시작하여,
점차 애니메이션을 통해 특정 주장과 근거로 범위를 좁혀나간다.
4.1.2 Selection-based Organization
대부분의 data articless는 스토리의 콘텐츠를 구성하기 위해, 섹션 기반 구조를 사용한다.
(섹션 - 몇 개의 짧은 paragraphs와 연관된 시각화를 포함)
텍스트와 비주얼 탐색의 싱크가 맞아야 한다.
4.1.1 Incremental Transitions and Parallel Structures
복잡한 정보를 쉽게 따라가고 이해할 수 있게 하는, 효과적인 스토리 전달 방식
■ Incremental Transitions
관찰 1
- 콘텐츠에 대한 이해를 돕기 위하여, 스토리에 전달된 data insights를 더 작은 단위로 나누어 점진적으로 커뮤니케이션하는 방법이 있다.
- 이 경우, 대부분 섹션에서는 데이터의 하나의 측면만 소개하게 된다.
■ Parallel Structures
관찰 2
- 한 스토리 내에서 병렬 구조가 일반적으로 사용되어, 여러 섹션에서 일관된 시각적 콘텐츠가 생성되는 케이스
4.2 Mappings Between the Text and Visuals
→ 제작자는 시각화와 애니메이션이 스토리와 일치하는지 지속적으로 확인해야 한다.
섹션의 텍스트가 AUV의 visual transitions에 상응하는지 이해하기 위하여,
- 수집된 corpus를 분석하고
- words와 phrase의 4개의 카테고리 (data property, data value, data operation, visual operation phrases)를 파악한다.
- 더 매력적인 visual stories를 위한 패턴을 이해하고 식별한다.
■ 텍스트 데이터의 words/phrases를 통해 파악한 데이터 패턴
(1) Data Property Phrases
(2) Data Value Phrases
(3) Data Operation Phrases
(4) Visual Operation Phraseseos
4.2.1 Data Property and Value Phrases
■ Data type (범주형/수치형)에 따른 구분
(1) Categorical data(범주형 데이터)
- 일반적으로 Data value(데이터 값)만 언급.
- 예) “most of the popular drinks have pudding as topping,”
(2) Numerical data(수치형 데이터)
- Data property와 data value 모두 자주 사용됨.
- 예) “the basketball players ranked between 50 to 100,”
4.2.2 Data Operation Phrases.
■ 4가지 타입의 analytical functions
(1) calculating derived value (e.g., "total", "average")
(2) finding extrema (e.g., "largest", "minimum")
(3) sorting (e.g., "rank", "from ... to ...")
(4) finding an alternative (e.g., "rest", "remaining")
4.2.3 Visual Operation Phrases
■ 선호하는 visual effects가 있을 경우 사용되는 문장
- 예) color, size, position과 같은 visual encoding 언어
(1) color - "highlight", "coloring"
(2) size - "width", "height"
(3) position - "distribute", "range", "across"
4.3 Summary
■ Content analysis - data stories with AUV
- section-based structure를 통해 narration과 visualizations를 구성
- 스토리의 점진적인 시각적 변화 & 역피라미드 및 병렬 구조
- 이야기 세그먼트와 시각화 사이의 싱크 필요
- Narration에서의 4가지 유형의 문구:
- data property
- data value
- data operation
- visual operation phrases
5. DESIGN DECISIONS
5.1 subtitle
- Formative study와 content analysis를 통해 AUV를 이용한 데이터 스토리에서 텍스트와 비주얼간에 연결이 높아야 한다는 것을 밝힘.
- '계획 단계'와' '최종 콘텐츠 제작 단계' 사이에 텍스트-비주얼 연결성을 유지하는 것을 관리하기 힘들고, 반복적인 작업이 요구됨.
- Planning stage (e.g. using a two-column script)
- Final content (e.g. using a section-based structure)
■ Design Decisions
D1. Language-oriented editing(언어 중심 편집)
- 스토리 텍스트에서 필요한 데이터 선택, 작업, 인코딩 및 애니메이션을 유추하여 원하는 시각화 및 애니메이션을 자동으로 생성하는 언어 중심 편집을 사용하여 빠른 프로토타이핑 및 콘텐츠 생성이 가능하다.
D2. Block-based editing (블록 기반 편집)
- 스토리, 시각화 및 애니메이션의 유연한 프로토타이핑을 가능하게 하는 동시에 해당 내용을 보장하기 위해 블록 기반 편집을 사용하여 내러티브의 섹션과 해당 비주얼이 전체 디자인 프로세스에 걸쳐 하나의 블록 내에서 구성된다.
6. DATA PARTICLES

■ DataParticles
- 'Language-oriented editing'과 'Block-based editing'을 사용하여 AUV로 데이터 스토리를 프로토타이핑하는 시스템이다.
■ DataParticles - Five UI components >
(1) The rich text editor - 자연어 텍스트 입력하여 스토리 전달
(2) The view panel - 입력한 텍스트 시각화 애니메이션
(3) The visual effects configuration panel - 애니메이션 효과 사용자 정의
(4) The block operation toolbox - 4가지 블록 작업 제공
(5) The dataset view panel - 시각화와 데이터셋 링크 확인
6.1 Natural Language to AUVs
■ 블록의 텍스트를 사용하여 AUV를 업데이트하는 4단계 파이프라인
(1) 관련 데이터 포인트 선택
(selecting the relevant data points,)
(2) 선택한 데이터 포인트에 대한 데이터 동작 수행
(performing data operations on the selected data points, )
(3) 비주얼 인코딩 지정
(specifying the visual encoding, )
(4) 블록 간 애니메이션 구성
(configuring the animations between blocks.)
■ 사용자가 블록에 글을 쓰는 동안 DataParticles는,
- 4가지 타입의 phrases를 파악하고,
- 텍스트의 pragmatic structure (실용적인 구조)을 이해하기 위한 파싱 작업을 수행.
- Parsed sentence를 기반으로, data selection / encoding 수행
- 위의 정보를 바탕으로, 블록의 visual state 결정
- 시스템은 visual states 간의 transition을 보여주는 애니메이션 생성.
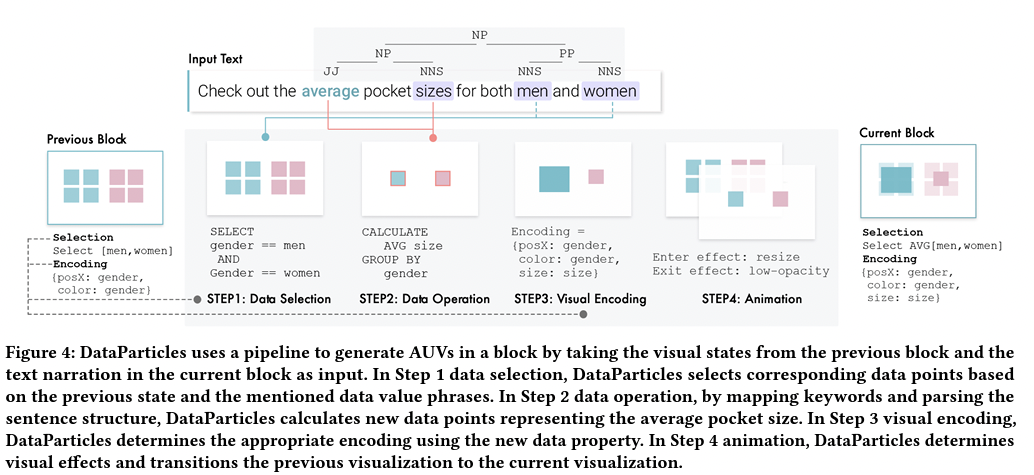
6.1.1 Data Selection
→ 텍스트의 word/phrases를 데이터셋의 data property 및 data value와 일치시켜 수행함.
■ Data type에 따라
(1) Categorical data(범주형 데이터) - 데이터 포인트에 Data value(데이터 값) 직접 매칭
예) “men”
--> "gender" property의 value에 해당 텍스트("men")을 매칭하고, 상응하는 데이터 포인트를 선택함.
(2) Numerical data(수치형 데이터) - Data property와 data value 모두 매칭
예) “the basketball players ranked between 50 to 100,”
--> "rank" property를 식별하고 언급된 range 만큼 (50 to 100) 데이터 포인트를 선택
- 시스템은 "larger than,", "over," "range,", "between" 과 같은 data values의 범위를 가리키는 여러 phrases들을 지원한다.
- DataParticles로 텍스트를 작성할 때, "#" 기호를 사용하여 데이터셋의 모든 data properties에 대한 dropdown list를 불러올 수 있다. 이를 통해 numerical property를 categorical property에 매핑할 수 있다.
6.1.2 Data Operations
→ DataParticles는 문장에서 data operations에 대한 phrases를 식별하고, 선택된 데이터 포인트에 해당되는 연산을 적용한다.
예) “The average pocket size for men.”
--> operation "average" 식별하고, 계산을 수행한다.
■ DataParticles는 3가지 종류의 data operations를 지원
- calculating derived values (파생 값 계산)
- finding the extreme (극단 찾기)
- finding an alternative (대안 값 찾기)
■ subgroup 연산 지원(groupby)
- Operations이 전체 selection이 아닌 subgroups에 적용되는 경우 지원
-문장 구조에 "group by" operation 이 있는지 판단 후, 각 그룹에 연산 적용
예) “The average intensities of different types of coffee are similar”
--> two properties 식별 (i.e., “intensities” and “types”)
--> pragmatic structure에 따라, "type"은 "intensity"의 dependent component, "average"는 "intensity"의 형용사이다.
--> sentence parsing을 통해, data operation "average"는 각 "type"의 "intensity"에 적용되어야 한다.
--> DataParticles는 selected data points를 "type"으로 group by 한 후, 각 그룹의 평균 "intensity"를 계산한다.
6.1.3 Visual Encoding
→ Data property phrases에서 가리키는 data attributes가 visual channels에 매핑되는 방법에 대한 설명.
→ 시스템은 특정 visual operation phrases에서 요청하는 인코딩을 우선순위로 수행하면서도
블록 전체에서 data property의 동일한 인코딩을 유지하기 위해 노력한다.
■ DataParticles에서 지원하는 3가지 visual encoding channels
- Size, Position, Color
■ greedy algorithm을 따라, 인코딩 할당
- 항상 가능한 최고의 visual channel을 새로운 data property에 할당한다.
■ property name에 따라 해당되는 visual channel을 지정
예: "width", "height" --> size encoding (Mackinlay's ranking rules 참고)
> Jock Mackinlay. 1986.
> Automating the design of graphical presentations of relational information.
> Acm Transactions On Graphics (Tog) 5, 2 (1986), 110–141.
6.1.4 Animations
■ 애니메이션
- selected / non-selected data points에 적용되는 staggered transitions (엇갈린 전환)
■ 시작 효과 & 종료 효과( 4 enter effects & 3 exit effects)
- data point가 시간에 따라 어떻게 변하는지 보여주어, 사용자가 스토리 진행에 따른 데이터의 발전을 확인할 수 있다.
6.2 Block-based Editing
■ To be updated
to be updated
6.2.1 Block Operations
■ To be updated
to be updated
6.3 System Walkthrough
■ To be updated
to be updated
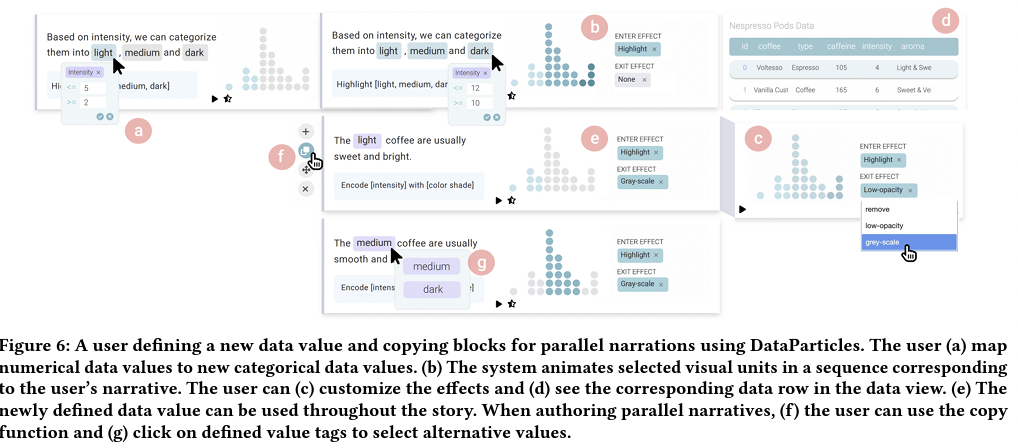
6.3.1 Initial Setup
6.3.2 Developing a Story by Adding Blocks
6.3.3 Defining a New Data Value
6.3.4 Using Parallel Structures by Copying Blocks
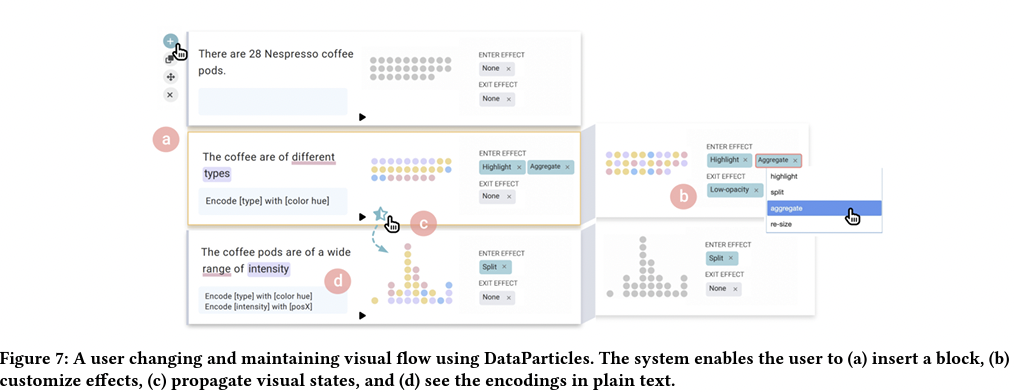
6.3.5 Changing and Maintaining Visual Flow
6.3.6 Review and Export
7. EXPERT EVALUATION
■ 아이템
설명
설명
7.1 Participants
■ To be updated
to be updated
7.2 Study Protocol
■ To be updated
to be updated
7.3 Results
■ To be updated
to be updated
7.3.1 Feedback on Language-oriented Authoring
■ To be updated
to be updated
7.3.2 Feedback on Block-based Editing
■ To be updated
to be updated
7.3.3 Workflows with DataParticles
■ To be updated
to be updated
7.3.4 System Limitations
■ To be updated
to be updated
7.4 Summary
■ To be updated
to be updated
8. DISCUSSION AND FUTURE WORK
■ 아이템
설명
설명
8.1 Supporting the Entire Creation Process
■ To be updated
to be updated
8.2 Support Visual Reasoning
■ To be updated
to be updated
8.3 Beyond Unit Visualizatinos
■ To be updated
to be updated
9. CONCLUSION
- 중요한 결론 -
- 이론적 함의 -
- 실재적 함의 (practical implications) -
- Future work
- (1)
- (2)
나의 의견
논문을 선택한 이유
(1) 논문 제목과 주제에 대한 흥미
- 작년에 Data point를 particle로 표현하여 데이터의 위치와 방향 등의 애니메이션을 적용하면 어떨까 하는 생각을 했었는데, 연구가 처음이라 어떻게 진행해야 할지 몰라서 잠정적으로 미뤄뒀었다. 생각했던 컨셉과 이름이 똑같은 연구 논문이 나와서 읽어보게 되었다.
- Data point를 particle이라 부르고 애니메이션을 추가한다는 내용은 같지만, 기존에 내가 생각하던 컨셉은 NLP보다는 numerical data에 집중하고 particle의 특성에 포커스 하는 것이라 약간 달랐다.
읽고 난 후 의견
- '데이터 스토리텔링'은 데이터 분석가, 데이터 기반 창작자뿐만 아니라 UX 설계자에게도 재미있고 흥미로운 분야라고 생각한다.
- '데이터 스토리텔링'을 시각화 하는 방법을 통해 데이터 리터러시를 증진시킬 수 있겠다는 생각이 들었다.
- 자연어의 데이터를 분석해서 애니메이션으로 전환한다는 내용이 재미있었다.
- 읽으면서 논문의 section들이 과하게 세분화되어있다는 느낌을 받았으나, 다르게 생각해 보면 이 툴에 대하여 자세하게 설명하고, 읽는 사람이 많은 정보를 내용의 혼동 없이 이해할 수 있도록 전달하고자 일부러 의도한 것이 아닐까 한다.



