구글 People+AI Research에서 2019년에 발표한 논문으로,
What-If Tool이라는 인터랙티브한 머신러닝 모델 탐색 시각화 툴에 대한 내용입니다.
읽은 날짜 2022.10.18
카테고리 #시각화논문리뷰, #DataVisualization, #XAI
The What-If Tool: Interactive Probing of Machine Learning Models
- Authors: James Wexler, Mahima Pushkarna, Tolga Bolukbasi, Martin Wattenberg, Fernanda Viégas, Jimbo Wilson
- DOI: https://doi.org/10.1109/TVCG.2019.2934619
- Keywords: Interactive Machine Learning, Model Debugging, Model Comparison
- Issue Date: 2019
- Publisher: IEEE Transactions on Visualization and Computer Graphics
ABSTRACT
배경: 머신러닝 시스템을 개발 및 배포할 때의 키챌린지는 다양한 입력값에 대한 성능을 이해하는 것이다.
목표: 오픈소스 애플리케이션인 ‘What-If Tool’ 이용하여, 실무자들이 최소한의 코딩으로 머신러닝 시스템을 탐구하고 시각화하고 분석할 수 있도록 한다.
방법: What-If Tool을 사용하여 실무자는 가설의 상황에서 모델의 퍼포먼스를 테스트할 수 있다.
- 다양한 모델과 입력 데이터의 여러 부분집합에 대한, data features 분석 및 모델 동작 시각화
- 머신러닝 fairness metrics(공정성 척도)에 따른, 머신러닝 시스템 측정
의의: What-If Tool 설계, 다양한 기관에서 실제 시스템을 사용한 내용에 대한 보고
1. INTRODUCTION
■ (배경/문제점) 머신러닝 실무자가 종종 머신러닝 시스템에 대해 검사, 분석해야 하는 내용들
- 언제 모델이 잘 동작하고, 언제 모델이 잘 동작하지 않는가?
- 입력 데이터가 어떻게 출력 데이터에 영향을 미치는지?
- Data point의 변경이 모델의 예측에 어떤 영향을 미치는가?
- 모델이 사람들 그룹 별로 다르게 동작하는가?
- 모델을 테스트하고 있는 데이터셋은 다양하게 이루어졌는가?
■ (목표/방법) What-If Tool(WIT)
오픈소스로 제공되며, 모델에 구애받지 않는, 모델 이해를 위한 interactive Visual Tool
■ What-If Tool 실행 방법 및 장점 요약
(1) TensorBoard, Jupyter, Colab. 에서 사용 가능, trained model, sample dataset 필요
(2) 기능 장점
Visual interface를 통한 ‘What-if’ 상황에 대한 반복적인 탐색 지원
Counterfactual reasoning (사실과 반대된 내용에 대한 추론)
Decision boundaries(결정 경계) 조사
로컬(단일 data point), 글로벌(전체 dataset) 에 대한 모델의 동작을 분석
Intersectional analysis(교차 분석) 시, 다양한 feature들이 조합된 data들로 data slicing지원
View 간의 유연한 전환 (input data와 model performance 뷰)
■ 이 논문에서는
(1) What-If Tool의 설계 및 (2) 머신러닝 시스템을 분석하는데 실제로 이 툴이 어떻게 적용되었는지 시나리오를 설명한다.
2. RELATED WORK
2.1 Model understanding frameworks
■ 머신러닝 성능을 이해하기 위한 툴
(Type 1) 모델의 내부 동작 방식을 보여줌. 주로 deep neural networks의 동작을 시각화
(Type 2) 머신러닝의 내부 동작을 ‘블랙박스’로 간주
-모델의 내부 구조에 의존하지 않고, 사용자가 입력과 출력을 탐색하도록 한다.
예) What-If Tool, Uber의 Manifold, IBM AI Fairness 360, Audit AI, GAMu 등.
■ What-If Tool의 차별화 포인트
(1) WIT는 유연한 프레임워크이다. (다른 모델은 특정 모델 이해에 초점을 맞춰 전문화되거나, 특정 유형의 알고리즘 분석만을 목표로 함.)
(2) 모델에 대해 머신러닝 fairness metrics(공정성 메트릭)를 계산
(3) 인터랙티브한 시각화 및 최적화 절차를 제공
2.2 Flexible visualization platform
■ Facets Dive 시각화
[ Datapoint editor ] 탭에는 Google의 Facets Dive 시각화 부분이 활용됨.
Facets Dive는 data encoding값을 빠르게 바꾸어 X, Y축 및 색상을 전환
로컬 메모리에 저장 및 계산하기 때문에, 민감한 데이터가 네트워크를 통해 전송되는 것을 막음.
데이터 사이즈에 제한을 두어, 원활한 탐색 가능. —> 단점을 장점으로 잘 포장했다는 생각이 듦.
3. BACKGROUND AND OVERALL DESIGN
■ 15개월 동안 내/외부 스터디 피드백을 통해 WIT를 설계함.
■ WIT 타겟 유저
초기→ 비전문가(데이터 저널리스트, 활동가, 시민 사회단체 등)
테스트 후→ 머신러닝 지식있는 사람을 대상으로 변경 (CS학생, 데이터 과학자, 프로덕매니저, 머신러닝 실무자)
■ 내부 스터디 (internal study)
— 텐서보드 플랫폼에서 동작하는 간단한 POC(proof-of-concept) 애플리케이션
— 4팀, 이미 텐서플로 모델을 구축하고 모니터 한 경험이 있는 8명의 개인
(1) 각 참가자의 모델과 데이터로, POC 애플리케이션 설정 평가
(2) 참가자가 시스템을 이용해 모델 퍼포먼스를 탐색하게 함. (think-aloud evaluation)
(3) 2-3주 동안 일반 업무에서, POC를 사용한 후, 반구조인터뷰 진행
(4) 피드백은 통합되어 다음 사용성 연구에 포함.
■ 외부 워크샵 - 1차
— WIT를 오픈소스화 한 후 진행, 머신러닝 초보자 5명
(1) 참가자가 모델 만들고 평가하고 싶은 데이터 직접 지참
(2) WIT 이용한 인터랙티브 데모를 통해 모델 이해 및 fairness explorations에 대해 토론 진행
(3) 이후, 참가자가 WIT를 모델과 데이터에 맞게 사용하는지 관찰.
(4) 피드백: WIT 사용에 대한 토론, 사후 오프라인 설문 (전반적인 기대와 경험을 파악)
■ 외부 워크샵 - 2차
— 하버드 대학에서 진행, 지역 데이터 사이언스, 머신러닝 커뮤니티에서 70명 이상 참여
(1) WIT 소개 후, 참가자는 Colaboratory notebooks 사용하여 참여.
(2) 프롬프트에 태스크 관련 지침을 띄워, 참여자가 수행하게 함.
(3) 피드백: 오프라인 설문 진행 (optional)
3.1 User Needs 5개
■ WIT 초기버전으로 수행한 사용성 테스트를 통해, 5가지 User Needs를 도출함.
N1. 최소한의 코드로 여러 가설을 테스트합니다.
N2. 모델 이해를 위한 매체로 시각화를 사용합니다.
N3. 모델의 내부 동작에 액세스 하지 않고 가설을 테스트합니다.
N4. 모델 성능에 대한 탐색적 교차 분석을 수행합니다.
N5. 여러 모델에 대한 잠재적인 성능 향상을 평가합니다.
(참고: 영어 버전)
N1. Test multiple hypotheses with minimal code.
N2. Use visualizations as a medium for model understanding.
N3. Test hypotheticals without having access to the inner workings of a model.
N4. Conduct exploratory intersectional analysis of model performance.
N5. Evaluate potential performance improvements for multiple models.
3.2 Overall Design
■ WIT 설치 및 사용 : TensorBoard 애플리케이션 일부, 또는 Jupyter 및 Colab. 노트북에서 extension사용
■ 초기실행 지원 (Out-of-the-box support)
처음 실행하는 경우, 초기실행지원이 제공되기 때문에 사용자에게는 어떤 코딩도 요구되지 않는다.
그러므로, WIT는 User Needs 1번 항목을 만족한다. ⇒ N1. 최소한의 코드로 여러 가설을 테스트합니다.
■ 인터페이스: {오른쪽-시각화 패널, 왼쪽- 컨트롤 패널}로 구성
왼쪽 컨트롤 패널 Tab 세 개: [Datapoint editor] [Performances & Fairness] [Features]
4. TASK-BASED FUNCTIONALITY
→ WIT 구현 및 WIT가 User Needs를 충족하는지에 대한 논의를 태스크 기반으로 설명함.
■ 두 모델 분류 예측 태스크 수행 비교
데이터셋: UCI Census dataset (인구 조사 데이터셋)의 data point 500개에 대해 두 모델 테스트
태스크: 인구 분류 - high (≥$50K/year) or low income
모델 1: 다층 뉴럴 네트워크 (multi-layer neural network)
모델 2: 단순 선형 분류기 (simple linear classifier)
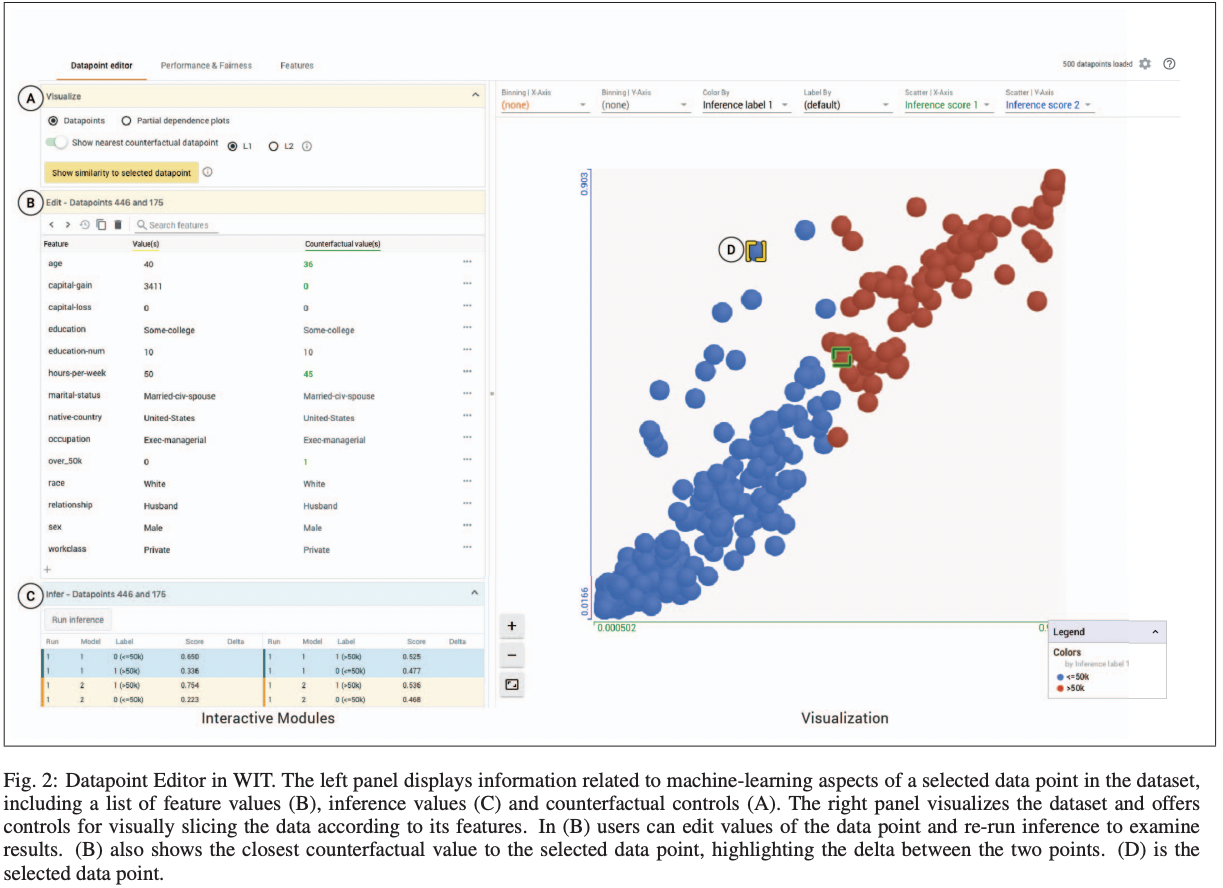
4.1 Exploring Your Data
→ WIT에서 data를 탐색하는 방법에 대한 설명
4.1.1 Customizable Analysis
■ [ The Datapoint Editor ] tab
Data point 및 추측한 값(inference value)을 보여줌
data point는 feature값에 따라 binned (구간화)되고, 색과 라벨이 정해지고, 위치가 정해진다.
데이터셋과 모델 결과 모두에서 사용자 지정 시각화 생성 가능
예) classification models: 분류 정확성, regression models: 추론 에러값에 따른 색상 설정
■ 시각화 예제
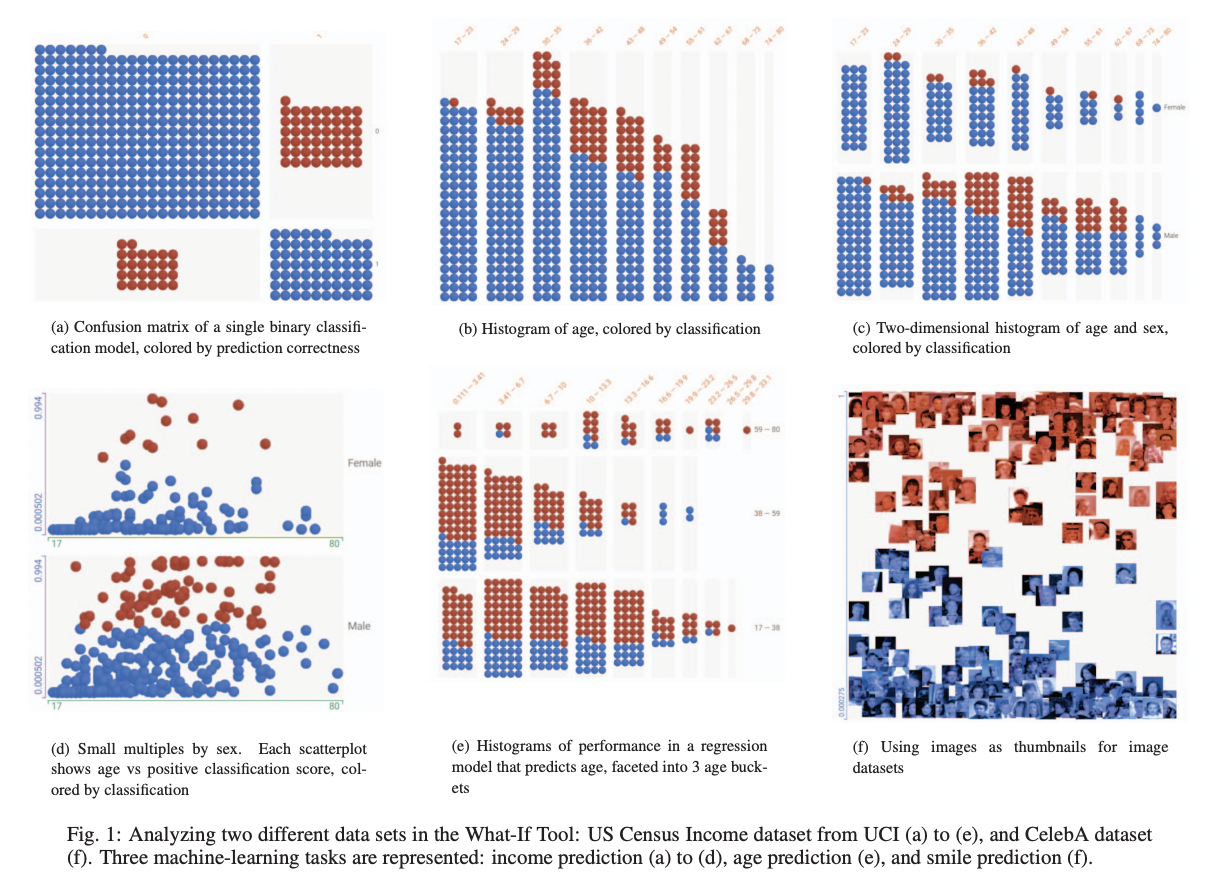
4.1.2 Features Analysis: Dataset Summary Statistics
■ [ Features ] tab
Facets Overview 시각화를 제공하여, dataset의 feature분포에 대한 요약 통계 및 차트를 제공.
subdataset에 따른 모델 성능을 설명할 때 유용하다.
→ User Needs 2번을 만족한다. N2. 모델 이해를 위한 매체로 시각화를 사용합니다.

4.2 Investigating What-If Hypotheses
→ 모델의 가설을 생성하고 테스트하는 법
4.2.1 Data Point Editing
■ WIT를 사용하여, 데이터를 쉽게 편집하고 모델의 추론에 미치는 영향을 확인
예) 은행 대출을 결정하는 모델에서 "X라는 사람이 여성이 아닌 남성이라면 대출을 받았을까?" (가설)
4.2.2 Counterfactual Reasoning
■ 모델의 추론 결과와 반대되는 방향(counterfactural)으로 질문하는 방법도 모델 이해에 도움이 됨.
예) 은행 대출을 결정하는 모델에서 "X라는 사람이 대출을 받기 위해 무엇을 변경해야 할까?" (역질문)
→ “대출을 받은 사람 X와 가장 유사한 사람은 누구입니까?”
■ WIT에서는 선택한 datapoint에 대한 Counterfactural 예제를 제시함.
단순한 distance metric을 사용하여, 입력 feature들에 대한 datapoint의 feature값 차이를 계산
• Numeric features: 두 datapoint값 차이의 절댓값을 전체 dataset에서 그 feature의 표준 편차로 나눔.
• Categorical features: 값이 같으면 0, 아닐 경우 해당 feature에서 두 예제가 동일한 값을 가질 확률

인구 조사 예제에서,
[노란색] 선택한 datapoint(부정적 추론결과)
[초록색] 선택한 datapoint와 가장 유사하지만 반대로 분류된 Data point (긍정적 추론 결과)
→ 왼쪽 Datapoint editor화면을 보고, 두 데이터의 feature 값 차이를 분석할 수 있음.
(초록색 datapoint는 capital-gain이 0이면, lower value보다 오히려 higher income으로 추정된다는 것을 알려줌)
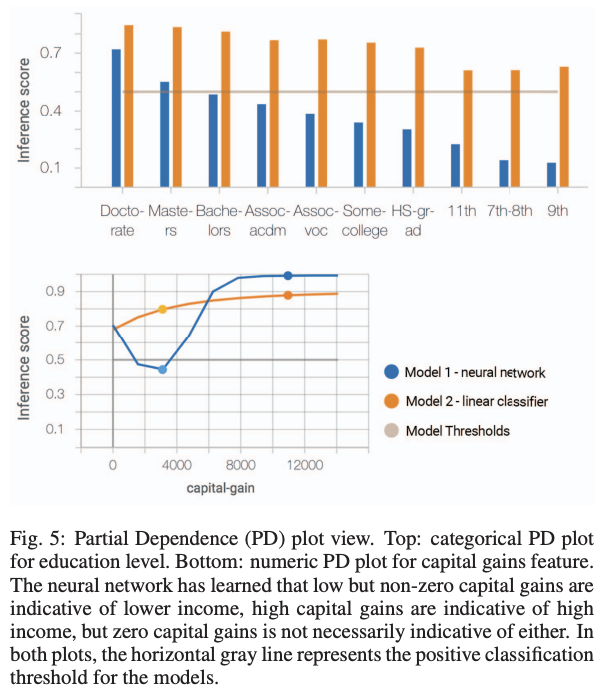
4.2.3 Partial Dependence Plots
■ 전체 값의 범위에 따라, feature 가 영향을 미치는 것이 어떠한가에 대한 이해를 도움.
• Numeric features: line charts
• Categorical features: column charts
→ 인구 조사 예제의 partial dependence plot
(위) ‘education’과 inference score
(아래) ‘capital-gain’과 inference score
모델 1은 capital-gane이 0과 high인 사람이 high-income을 갖는다고 나옴.
4.3 Evaluating Performance and Fairness
■ [ Performance + Fairness ] tab.
모델 성능을 분석하고, data subset에 대한 성능을 비교할 수 있는 performance table을 제공함.
단일 feature 분석, 두 feature 교차 분석 모두 지원
→ User Needs 4번, 5번을 만족한다.
N4. 모델 성능에 대한 탐색적 교차 분석을 수행합니다.
N5. 여러 모델에 대한 잠재적인 성능 향상을 평가합니다.
4.3.1 Performance Measures
performance table은 사용자의 task에 적합한 performance measure를 제공.
| Model Type | Performance Measures |
| Binary classification | Accuracy False positive percentage False negative percentage Confusion matrix ROC curve |
| Multi-class classification | Accuracy Confusion matrix |
| Regression | Mean error Mean absolute error Mean squared error |
4.3.2 Cost Ratio
컨텍스트에 따라 머신러닝 시스템의 Cost 비율을 다르게 설정할 필요가 있음.
예) 의학적 맥락에서는 ‘민감도’가 높은 것이 선호됨. - 참고: Sensitivity = TP / (TP+FN)
WIT에서는 dataset에 대한 모델 추론 결과가 주어지면, 최적의 threshold값을 찾도록 Cost Ratio를 변경할 수 있다.
4.3.3 Thresholds and Fairness optimization Strategies
Fairness optimization strategies(공정성 최적화 전략)를 탐색할 수 있다.
아래 표 2는 binary classification을 위한 Fairness Strategy이다.
| Fairness Strategy | Definition |
| Single Threshold | A single threshold for all data points based solely on the specified cost ratio. |
| Group Thresholds | Separate thresholds for each slice based solely on the specified cost ratio. |
| Demographic Parity | Similar percentages of data points from each slice must be predicted as positive classifications |
| Equal Opportunity | Similar percentages of correct predictions must exist across each slice for those data points predicted as positive classifications. |
| Equal Accuracy | Similar percentages of correct predictions must be made across each slice. |
(아래 오른쪽 이미지) Fairness Strategy의 Demographic Parity에 따라, 성별에 따른 차를 없애기 위해, threshold값을 조정한 경우.
UCI Census dataset은 성별 간 불균형이 있어 남성이 여성보다 고소득자로 분류될 가능성이 높다.

4.4 Comparing Two Models
■ [ Performance + Fairness ] tab에서 제공하는 성능 측정 및 시각화는, 두 모델의 비교를 지원한다.
4.5 Data Scaling
■ WIT에 로드할 수 있는 data points의 수 (표준 랩톱 환경) → 정확히, 어떤 환경인지 나오지 않음.
-tabular data (테이블 형식 데이터), 10-100개의 숫자/문자 입력 ⇒ WIT에서 100k data points 처리 가능
-작은 이미지(78x64 pixels) ⇒ WIT에 2000 data points 로드 가능
-feature 수와 각 feature사이즈가 메모리 제약의 요인이므로, dataset에 따라 달라짐.
5. CASE STUDIES (세 가지 케이스 스터디)
5.1 Regression Model from an ML Researcher
대기업의 ML researcher가 WIT를 사용하여 production setting에서 regression model을 분석한 사례.
WIT로 각 feature에 따라 모델의 regression score가 어떻게 변하는지 확인하기 위하여, partial dependence plots확인 → 특정 feature는 이 모델에서 전혀 고려하지 않는다는 것을 알아냄.
WIT 덕분에 모델 문제점을 파악하여, 모델의 버그를 수정함.
5.2 Regression Model from an ML Researcher
대기업의 소프트웨어 엔지니어가 WIT를 사용하여 두 버전의 regression models를 비교한 사례.
WIT의 시각화 및 선택한 data point 추론 결과를 통해, 모델 1이 모델 2보다 거의 항상 예측값이 크다는 것을 알아냄. → 모델 1의 입력 값에서 측정한 첫 번째, 마지막번째 값이 항상 스위칭되는 오류 발견
WIT 덕분에 모델 문제점을 파악하여, 모델의 버그를 수정함.
5.3 Regression Model from an ML Researcher
MIT 학생 그룹에서, 과제 프로젝트에 WIT를 사용하여 보스톤 경찰서의 불심검문(stop and frisk) 관행에 대한 공정성을 분석한 사례.
2011-2015년까지 150,000개 이상의 기록 데이터를 바탕으로 linear classifier model을 만듦.
WIT을 이용해 개별 data point의 Counterfactual Reasoning (반대 사실 추론)을 진행 → 경찰관 ID 만 변경해도, 결과가 바뀔 수 있다는 것을 알아냄. (나이,성별,인종 보다, 경찰관ID 가 더 영향이 큼)
WIT의 [ Performance + Fairness ] tab을 이용하여 다른 그룹 간의 Fairness를 측정함.
→ 특정 그룹의 사람이 불심검문에서 불리하다는 것을 발견함.
(White: 유리함, Hispanic: 약간 유리함, Black: 약간 불리함, Asian: 매우 불리함)
6. LESSONS FROM AN INTERACTIVE DESIGN PROCESS
■ 15개월 동안 스터디를 통해 WIT 기능을 3가지 핵심 workflow로 설정.
(1) 가상 시나리오 테스트 (testing hypothetical scenarios)
(2) 데이터에 대한 일반적인 이해 (general sense-making around data)
(3) 성능 및 공정성 평가 (evaluation of performance and fairness)
■ Partial dependence plots와 같은 컴포넌트나 counterfacturals와 같은 개념은 사용자가 처음 접하게 되는 내용이므로, in-application documentation을 제공
■ [ Fairness + Performance ]에서 threshold값 변경 시, data point 시각화도 즉시 재배열되었었으나, 이 부분이 혼동스럽다는 사용자 피드백을 통해, confusion matrix 및 ROC curve를 보여주는 것으로 교체함.
7. CONCLUSION AND DIRECTIONS FOR FUTURE RESEARCH
- 중요한 결론 - WIT를 통해 사용자는 그래피컬하게 머신러닝 시스템을 분석할 수 있고, WIT는 다양한 기능을 지원한다.
- 이론적 함의 - 머신러닝 공정성과 관련된 메트릭을 평가하고 최적화한다.
- 실재적 함의 (practical implications) - 케이스 스터디를 통해, WIT가 모델의 버그를 발견하고, 모델에 대한 통찰력을 제공하는 것을 확인함.
- Future work
- (1) 머신러닝 모델의 내부 동작에 대한 정보를 사용할 수 있도록 개선하는 방향
- (2) 툴 사용에 대한 진입장벽(머신러닝과 데이터 과학에 대한 전문성)을 낮출 것
나의 의견
논문을 선택한 이유
(1) 기술을 시각적으로 표현하고 설명한다는 것에 관심이 있기 때문에, What-if analysis에 대한 시각화라는 이 논문의 주제가 흥미로워 보였다.
(2) 구글의 People+AI Research에서 쓴 논문이라 내용과 퀄리티가 궁금했다.
읽고 난 후 의견
- 대부분의 경우, 내용의 중복이나 늘어짐 없이 설명이 간결하여 읽기 좋았다.
- 시각화 툴을 설명하기 위하여, 샘플 데이터셋과 태스크를 예로 든 방법이나,
- 툴을 활용한 사례(케이스 스터디)를 제시한 것이 흥미로웠다.
- 케이스 스터디가 (1) 모델 버그 수정, (2) 데이터 분석에 대한 사례를 골고루 담고 있어서 좋았다.
- 이 툴의 차별화 포인트라고 할 수 있는 'Fairness(공정성)' 관련 부분의 설명이 부족하여 아쉬웠다.
- 몇몇 부분에서 내용이 명확하지 않고 모호해서 이해하기 어려웠다.
- 예를 들어, Background and oveerall design파트에서 어느 실험을 먼저 수행했는지, 몇 차례 수행했는지 두괄식으로 설명되지 않아서 내용 이해가 어려웠다.



