블로그와 주류 미디어사이에서 짧은 문구(short phrases)와 밈(meme)이 퍼져나가는 다이내믹스(역학 관계)를 분석한 연구입니다.
읽은 날짜 2023.08.20
카테고리 #DataMining, #SocialComputing, #News
Meme-tracking and the dynamics of the news cycle
- Authors: Jure Leskovec, Lars Backstrom, Jon Kleinberg
- DOI: https://doi.org/10.1145/1557019.1557077
- Keywords:
- Issue Date: June 2009
- Publisher: KDD '09 (Proceedings of the 15th ACM SIG KDD international conference on Knowledge discovery and data mining)
ABSTRACT
배경 > 문제점 > 목표(RQ) > 방법 > 평가 > 결과 > 의의
(배경)
새로운 토픽, 아이디어와 'memes(밈)'을 트래킹하는 것은 웹의 전반에 걸쳐 흥미로운 이슈이다.
최근 연구(당시 2009년)에서는 긴 시간(long time scales)동안 어떻게 토픽이 변해가는지를 트래킹하고, 새로운 토픽의 갑작스러운 등장(abrupt spikes)을 추적하는 방법론을 개발했다.
(문제점)
이러한 접근법의 문제점은, 우리가 뉴스나 사건을 인지하는 시간 단위인 '일(days)' 단위의 시간 흐름에따라 널리 퍼졌다가 사그라드는 콘텐츠를 식별하는 데에는 적합하지 않는 것이다.
(RQ/목표)
온라인 텍스트를 통해 날것으로(intact) 전달되는, 비교적 짧고 구별가능한 문구들을 위한 프레임워크를 개발한다.
확장 가능한(scalable) 알고리즘을 개발하여 이러한 문구의 텍스트 변형(textual variants)를 클러스터링함으로서, 매일 일어나는 memes의 광범위한 클래스들과 풍부한 변형을 식별한다.
이러한 meme-tracking approach 가 뉴스 사이클의 일관된 표현(coherent representation)을 제공할 수 있다는 것을 보인다.
(방법)
우리는 3개월 동안 160만개의 (1.6 million) 주류 미디어 사이트와 블로그를 트래킹하여 총 900만 (90million) 개의 아티클을 수집하였고, 뉴스 사이클에서 새롭고 지속적인 시간적 패턴(temporal patterns)을 발견했다.
(결과)
- 각 문구의 대한 최고의 관심도에 이르기까지 뉴스 미디어와 블로그 사이에 일반적으로 2.5시간의 시차(lag)가 있으며,
- 전체 정점(peak)을 중심으로 다른 행동들이 나타나고,
- 문구에 대한 관심이 뉴스 미디어에서 블로그로 옮겨 갈 때(handoff), "심장박동" 같은 형태의 패턴이 나타나는 것을 관찰했다.
- 또한, 시스템이 보여주는 시간적 변화의 종류에 대한 수학적인 모델(mathematical model)을 개발하고 분석했다.
1. INTRODUCTION
■ < 선행 연구에서 토픽, 아이디어, 및 밈을 트래킹하기 위한 두 가지 방법론 >
두 가지 극단적인 케이스에서 유용함.
(1) 일반적인 토픽 트렌드 (probabilistic term mixtures)
- 시간에 따른 일반적인 토픽 트렌드를 식별하는데 성공적
(2) 블로그에서의 간략한 정보 전파
- 블로그간의 하이퍼링크를 식별하고, rare named entities를 추출하는 것
- blogosphere(블로그 집합)들을 통해 전파되는 간략한 정보들을 트래킹하는데 사용된다.
■ 이 논문의 초점 => 밈(meme)과 문구(short phrases)
- 두 극단의 케이스 가운데에 존재하는 케이스
- 일상적으로 사람들이 웹의 뉴스, 블록, 웹사이트와 지속적으로 상호작용하면서 발생하는 시간적, 텍스트적인 범위(temporal and textual range)
■ 밈(meme)과 문구(short phrases)
- 짧은 단위의 글, 짧은 문구들과 "밈(meme)"은 토픽과 사건의 시그니처 역할을 한다.
- 짧은 문구와 밈은 웹의 주류 미디어에서 블로그로, 또는 그 반대로 블로그에서 주류 미디어로 확산된다.
- 사람들은 짧은 문구와 밈을 통해 뉴스와 시사(current events)를 경험한다.
- 상대적으로 안정되고 넓은 범위의 토픽 가운데 사람들의 관심을 끌고, 더 많은 관심을 받기 위한 목적으로 스토리라인이 생겨나며 이런 스토리라인은 총체적으로 해설자(commentators)들이 뉴스 사이클이라고 부르는 효과를 만든다.
- 새로운 스토리 라인들은 계속 등장/성장/소멸 하므로 이러한 시간적, 주제적인 공감대에서의 다이나믹한 정보를 트래킹하는 것은 어렵다.
- 그 결과로, 뉴스 사이클의 다이나믹스(역학관계)는 미디어 및 정치 과정의 연구자들의 관심을 많이 받는 주제였지만, 대부분 정성적인 측면에 집중되었다.
- 뉴스 사이클의 전반적인 정량 분석의 기법은 상대적으로 부족했다.
■ 이 연구에서는
웹을 따라 전파되는 정보의 단위를 트래킹하기 위한 방법을 개발한다.
우리의 접근법은, 먼저 짧은 구별가능한 문구를 확장 가능하게(scalably) 식별하는 최초의 방법이다.
이러한 문구들은 시간이 지나도 온라인 상에서 상대적으로 안전하게 유지된다.
- 이 연구는 온라인 주류 미디어와 블로그 미디어를 본질적으로 완벽하게 커버하는 방대한 데이터셋에서 수행되었다.
- 우리는 데이터셋에서 이러한 텍스트 요소(textual elements)를 자동으로 식별하고, 실제로 볼 수 있게 했다.
- phrases(구문)을 이용해 작업하는 것은 topic models와 named entity라는 두 극단을 자연스럽게 보완(보간)한다.
(1) 특징적인 phrases(구문)들은 짧은 기간의 시간에 걸쳐 상당한 다양성을 보여준다.
이에 비해 광범위한 어휘들은 (상대적으로) 유지된다.
그 결과, 일반적인 주제를 매일매일 달라지는 스레드나 밈의 large collection으로 분해할 수 있다.
(2) 이런 distinctive phrases는 충분히 풍부하기 때문에 대규모 밈 컬렉션의 "tracers(추적자)" 역할을 할 수 있다.
- single named entity의 출현/사라짐이 발생할 때, 이와 관련된 밈의 작은 컬렉션들에만 주의를 한정시키지 않을 수 있다.
- 알고리즘적인 관점에서, 이러한 특징적인 문구들은 각기 다른 밈에서 analogue of "genetic signatures(유전적인 사인)"의 역할을 한다.
- 유전적인 사인과 마찬가지로, 시간이지나면 이러한 문구들도 변이를 겪는다.
- 결과적으로, 이 접근법의 핵심적인 계산 도전은 (a central computational challenge) 이러한 distinctive phrases에서 모든 변형을 식별하고 추출하는 robust way를 찾고, 이를 함께 그룹화 하는 것이다.
- 우리는 이 문제의 scalable algorithms를 개발하였고, 밈이 single phrases의 모든 변형을 포함하는 클러스터에 대응하도록 하였다.
2. Algorithms for Clustering Mutational Variants of Phrases
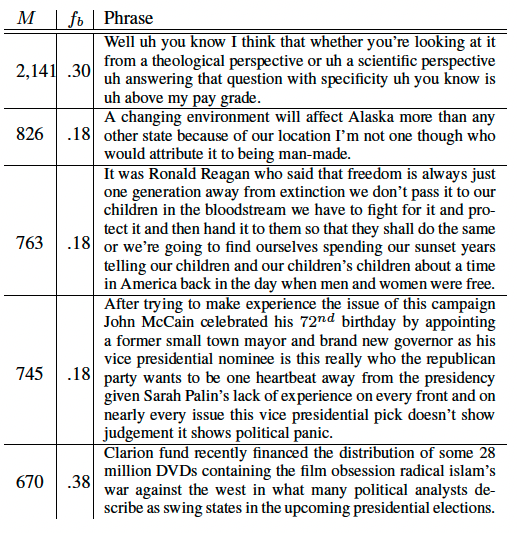
3개월 동안 100million(1억)개의 articles에 대하여 corpus(말뭉치)들의 quotes의 textual variants를 identify하고 clustering하기 위한 알고리즘.
■ 용어 정의 (terminology)
- item => each news article or blog post
- phrase => item에서 한번 이상 등장하는 quoted string
- goal => phrase clusters를 생성하는 것
- phrase graph를 구축 => phrase가 node, 비슷한 phrases를 연결한 directed edges 로 구성되는 graph
- graph를 partition으로 나눔. => components가 phrase clusers로 구성되도록 나눔.
- quote data에서 textual variant를 발췌 => phrase p 가 contiguous subsequence of the words in phrase q.
phrase graph를 구축해서 이런 inclusion relation(포함 관계)가 있는지 찾음.
2.1 The phrase graph
■ Preprocessing
lower bound L => word-length of phrases we consider
lower bound M => frequency (full corpus에 등장 횟수)
각 single domain에서 최소 0.25 fraction 나오는 phrases는 삭제. (조사해보니 이 이정도 자주 나오는 frequent phrases는 주로 spammers에 의해 생산된 것. )
■ DAG (Directed Acyclic Graphs)
Preprocessing 후 graph G 를 구축.
G => set of quoted phrases.
edge (p, q) => p: shorter - q: longer than p
k-word consecutive overlap between the phrases we use k=10 (p, q)
2.2 Partitioning the phrase graph
■ Proposition (명제)
DAG partitioning 작업은 NP-hard 이다.
(그러므로 매우 시간이 오래 걸리고 힘들다.)
*참고: NP-hard
https://ko.wikipedia.org/wiki/NP-%EB%82%9C%ED%95%B4
2.3 An alternate heuristic
DAG partitioning 하는 작업은 매우 힘들기 때문에 (intractability), 대신 class of heuristics를 개발했다.
> 주요 아이디어는 DAG의 각 노드에서 하나의 연결만을 선택하는 것으로, 이 연결만을 기반으로 작은 그룹들을 만들 수 있게 된다.
이런 방식으로 그룹을 만들 때, 우리는 각 그룹 안에서 연결이 얼마나 강한지를 기준으로 평가했다. 예를 들어, 가장 짧은 문장으로 연결하는 방법은 기존 방법보다 9% 더 좋았다. 가장 자주 등장하는 문장으로 연결하는 것은 12% 더 좋았고, 가장 많은 연결을 갖는 그룹으로 노드를 추가하는 방법은 13% 더 좋았다. 하지만, 다른 알려진 방법인 simulated annealing(담금질 기법)을 사용했을 때는 향상되지 않았다.
이 결과는 우리가 시도한 방법들이 꽤 효과적이라는 것을 보여준다.
(>> 예전에는 머신러닝이 없었으므로 이 연구에서 DAG를 이용해서 클러스터링을 했었다.)
2.4 Dataset description
■ 데이터셋 설명
- 3달 동안의 자료(8/1 - 10/31, 2008)
- 온라인 메인스트림, 소셜 미디아 activity의 1 million(100만)개 documents per day
총 90 million(9000만)개 documents (blog posts, news articles)
- Spinn3r API 사용해서 1.65million 의 다른 사이트 자료
- 총 total 390GB 메인스트림 뉴스(Google News 의 파트 - 20,000개 다른 사이트) + 1.6million blogs forums and other media sites.
- 총 112 million quotes and L < 4, M < 10
- Clustering the phrases => 9 hours 걸림.
이 외..노드 갯수 등.
3. Global Analysis: Temporal Variation And a Probabilistic Model
phrase clusters를 가지고 있는 상황에서, individual elements of news cycle을 구축한다.
■ Thread 정의
- 주어진 phrase cluster와 관련된 스레드
=> 클러스터의 일부 문구를 포함하는 모든 항목 set of all items (뉴스 아티클, 블로그포스트) 의 집합
- 시간이 지남에 따라 모든 스레드를 추적
- individual temporal dynamics (개별적인 시간 역학) 과 각각 서로간의 interactions를 고려하였음.
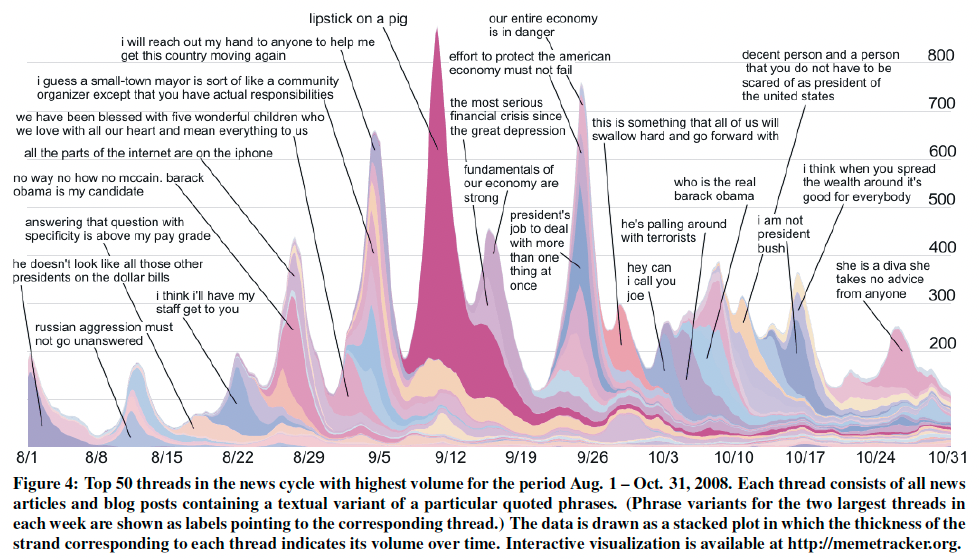
■ <Figure4> 설명
- 위의 <Figure 4> 이미지는 2008년 8월 1일부터 10월31일까지 3개월 동안 가장 큰 스레드 50개를 묘사한 것으로,
우리의 접근 방식을 사용하여 자동으로 생성하고 자동으로 레이블을 지정했다.
- 그래프 스타일: 누적 플롯 (stacked plot)
- 각 스트랜드(strand)의 두께: 시간 경과에 따른 해당 스레드의 부피 (총 면적=부피)
=> 이 이미지를 통해, 상승 및 하락 패턴이 실제로 블로그와 미디어가 공통 스토리 라인에 연속적으로 초점을 맞추거나 초점을 맞추지 않는 패턴을 알 수 있다.
■ 주목할 점
- 데이터셋의 article과 post들의 총 개수, 총 quotes 수가 대략 모든 주중 날짜에 대해 일정하다.
- <Figure 4>에 있는 시간적 변화(temporal variation)은 매일 글로벌 뉴스 및 블로그활동의 전체 양이 변화한 게 아님.
- 오히려 curve의 위쪽이 높은 기간은 key stories에 대한 convergence(수렴)정도 degree가 높다.
- 낮은 기간은 관심이 많은 기사에 분산되었음을 의미한다.
- spikes와 phrases는 많은 관심을 트리거한 정확한 이벤트와 순간을 가리킴.
3.1 Global models for temporal variation
■ 모델링 관점
- 모델링 관점에서 시간이 지남에 따라 이러한 유형을 정의
- <Figure 4>의 곡선을 정확하게 맞추려고 하기 보다는, 모델링 관점에서 대체로 유사한 모델을 생성하는 기본 성분 찾기.
■ <Figure 4>의 뉴스 데이터와 유사한 역학을 표현하는 자연 시스템
(1) 뉴스 주기를 생태계 내에서 일종의 종 상호작용으로 상상
- 이 경우, 스레드는 자원(시간이 지남에 따라 지속적인 미디어의 관심)을 놓고 경쟁하는 종의 역할을 하게됨.
(2) 모낭 발달과 같은 특정 종류의 생물학적 조절 메커니즘
- 이 경우, 스레드는 몇 개의 세포가 어느 시점에서 우세한 경향이 있는 환경에서의 세포 의 역할
■ 뉴스 주기의 다이내믹스(역할) 모델에서 고려해야 할 것
- 서로 다른 소스가 서로를 모방(imitate). 하나의 스레드가 큰 볼륨을 갖게 되었을 때, 다른 스레드를 채택하며 지속 성장할 수 있음.
- 스레드가 강력한 recency effects에 의해 동작.
즉, 오래된 스레드보다 새로운 스레드가 선호됨.
3.2 Analysis and simulation results
■ 분석한 뉴스 스레드의 양상에 따른 모델을 만든 것에 대한 내용
- 연구자들이 생성한 모델이 실제 뉴스 사이클 데이터에서와 비슷한 변동을 생성한다는 것을 시뮬레이션을 통해 확인함.
- 아래의 <Figure 5> 참고.

4. Local Analysis: Peak Intensity And News/Blog Interactions
4.1 Thread volume increase and decay
time t 에서의 스레드 볼륨 => 그 timestamp t에서 items 개수
스레드 p가 있을 때 peak time => tp (tp는 peaktime이 발생하는 time의 median값)
4.2 Time lag between news media and blogs
뉴스와 블로그 둘 다 peak 지점을 0에 놓고 데이터를 비교했을 때,
뉴스의 경우 중앙값이 왼쪽에 있고 블로그는 중앙값이 오른쪽에 있다.
=> 즉, 뉴스가 먼저 증가하고 감소한다.
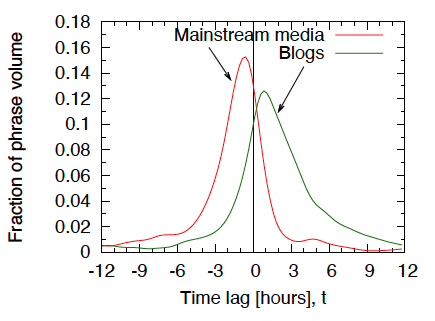
4.3 Handoff of phrases from news media to blogs
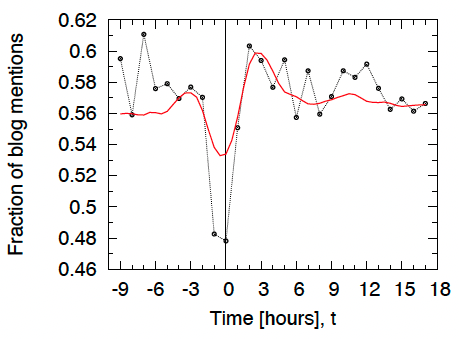
뉴스 미디어에서 블로그집단(blogsphere)로의 phrase의 역학 및 전환을 조사하기 위해, 다음 실험을 수행했다.
- 상위 1000개의 스레드를 가져와서, 모두 tp=0 시점에 정점에 도달하도록 정렬한 다음, 각 스레드의 총 볼륨에 대한 블로그 볼륨의 비율을 시간의 함수로 계산.
- 결과: <Figure 9> 블로그와 주류 미디어 간에 진동하는 '심장 박동' 과 같은 역학 관계를 보임.
- 블로그 볼륨의 비율은 처음에는 일정하지만, 초기 블로거들이 특정 문구를 엉급하면서 peak 도달 3시간 전 급격히 상승함.
- 뉴스 미디어가 합류하면 t = -1 전 후로 블로그 볼륨이 급격히 떨어짐.
- 뉴스 미디어가 이 문구를 삭제하기 시작하고 블로그는 계속 이 문구를 언급할 경우 t=0 이후에 다시 증가세로 돌아선다.
- 블로그의 경우 주로 t= 2.5경에 peak를 찍고, 6-9시간이 지나면 안정화 됨.
- peak 이전 (t<=-6) 에는 56%로 대체적으로 constant fraction(일정한 비율)인데, peak 이후(t>=9)에 더 높음.
- 즉, 뉴스 미디어가 합류 후 다시 흐름에서 빠져나간 이후에도, 블로그 집단에서는 지속적으로 효과가 있음.
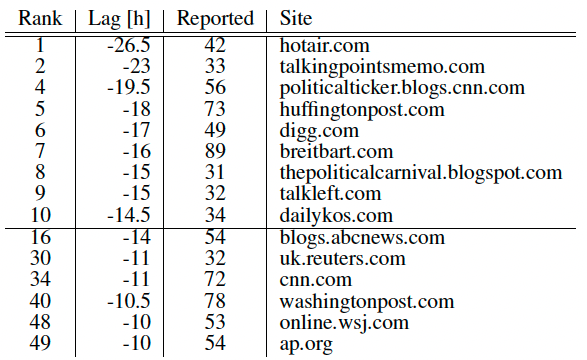
4.4 Lag of individual sites on mentioning a phrase
■ 구문을 언급하는 개인 사이트
- 특정 스레드에 대한 사이트의 지연 시간(lag) = (사이트가 관련 quote를 처음 언급하는 시간 - 구문의 peak time)
- 이 경우, lag이 음수이면 해당 사이트가 peak time 전에 quote를 언급했다는 뜻.
- 아래의 Table1을 보면, 구문에 대한 초기 언급자는 주로 블로그와 독립 미디어 사이트이며, 그 뒤에 대형 미디어 조직이 따른다.
4.5 Quotes migrating from blogs to news media
- 대부분의 문구는 뉴스 미디어에 먼저 등장한 후 블로그로 확산되어 더 오랜시간 논의된다.
- 그러나 이와 반대로 blogsphere에서 등장하여 뉴스 미디어에 채택되는 문구도 있다.
5. CONCLUSION
- 중요한 결론
- 이 연구에서는 온라인 텍스트를 통해 이동하는 문구를 추적하기 위한 프레임워크를 개발했다.
- 이를 통해, 뉴스와 블로그 사이의 '심장 박동' 형태의 전환과 함께, 뉴스 미디어와 블로그에 대한 관심이 peak에 도달할 때까지 일반적으로 2.5시간의 지연(lag)을 관찰했다.
- 시스템이 나타내는 시간적 변화에 대한 수학적 모델을 개발했다.
- 정보는 대부분 뉴스에서 블로그로 전파되며, 데이터의 3.5% 사례만이 블로그에서 처음으로 지배적으로 나타난 후 주류 미디어로 전파되었음을 발견했다. - 이론적 함의
- 글로벌 뉴스 주기와 주류 미디어와 소셜 미디어 간의 정보 전파 다이내믹스(역학)에 대한 최초의 정량적 분석이다.
- 9천만 개의 기사 컬렉션(지금까지 중 온라인 뉴스에 대한 가장 큰 규모의 데이터) 분석을 수행했다.
- 온라인 문구의 텍스트 변형을 식별하고 클러스터링 하기 위한 알고리즘을 제시했다. - 실재적 함의 (practical implications) - meme tracking에 대한 이 연구의 접근 방식은 이전에 해결이 불가능했던 질문들의 답을 찾을 수 있게 한다. 또한 뉴스 사이클의 다이내믹스에 대한 수학적 모델은 미디어 분석가에게 유용할 것이다.
나의 의견
논문을 선택한 이유
(1) 교수님께서 추천해주셔서 읽어보게 되었다. 처음에는 2009년도 논문이라 지금과 트렌드가 너무 다르지 않을까? 하는 생각이 들었는데 사실 고전을 아직도 읽는 이유가 있듯 이 논문도 유익했고 새로웠다.
읽고 난 후 의견
- 유행하는 문구와 밈은 과연 어디에서 시작해서 어떻게 peak를 찍고 소멸하는가에 대한 분석 연구이다.
- 이런 연구를 하려면, 일단 사회 현상에 대하여 "그려러니" 하는 마인드 보다는 "어떻게? 왜?" 를 궁금해 하는 호기심이 있어야 겠다는 생각이 든다. 이런 것을 궁금해 하며 분석하는 사람이 데이터 사이언티스트가 되는 것이지 않을까!
- 동일한 내용이라도 이를 시각화 하여 전달하는 것은 큰 인사이트를 전해준다. 숫자와 친한 사람이라면 분석 내용만 보고도 감탄할 수 있지만 숫자와 친하지 않다면 시각적으로 전달하는 것이 내용 이해에 효과적이다.
- 요즘은 유행이 다른 소셜 미디어를 통해 속속 생겨나고 빨리 시들어 버린다. 요즘 기준으로 이 연구와 비슷한 그래프를 그리면 엄청 다이나믹 하게 나오지 않을까 한다.



