뉴스 기사에서의 Coverage diversity를 시각적으로 분석하기 위한 시스템인 News Kaleidoscope 에 대한 연구입니다.
읽은 날짜 2023.07.20
카테고리 #시각화논문리뷰, #DataVisualization, #뉴스시각화
News Kaleidoscope: Visual Investigation of Coverage Diversity in News Event Reporting
- Authors: Aditi Mishra; Shashank Ginjpalli; Chris Bryan
- DOI: https://doi.org/10.1109/PacificVis53943.2022.00022
- Keywords:
- Issue Date: June 2022
- Publisher: 2022 IEEE 15th Pacific Visualization Symposium (PacificVis)
ABSTRACT
배경 > 문제점 > 목표(RQ) > 방법 > 평가 > 결과 > 의의
(배경)
Coverage diversity란, newsworthy한 이벤트가 발생했을 때 미디어의 기사들이 해당 이벤트의 매우 다양한 부분에 대해 리포트하는 것을 의미한다.
(RQ/목표)
Event reporting에서 coverage diversity에 대해 조사하기 위해서, News Kaleidoscope라는 시각적 분석 시스템을 개발했다.
(방법)
News Kaleidoscope는 많은 백엔드 언어처리 기술을 통합하여 잘 조직된 하나의 시각화 인터페이스로 합했다.
News Kaleidoscope는 시각화 전문가가 아닌 사람들에게 맞춰 디자인되었고,
subselection analysis(하위수준 분석)에 기반한 analytic workflow(분석 워크플로)를 채택하여, 뉴스 기사의 이단계 수준(second-level)의 features을 추출하여 Coverage diversity를 위한 좀 더 자세하고 미묘한 분석을 제공한다.
(평가)
News Kaleidoscope를 안정적으로 평가하기 위하여 우리는 세 가지 user studies를 수행했다.
(1) 뉴스 전문가를 대상으로 수행한 유저스터디
-> journalism-savvy users를 타겟으로 한 스터디
(2) 뉴스 초보자를 대상으로 수행한 후속 연구
-> 전반적인 시스템 평가 및 journalism-agnostic users를 위한 인사이트를 위한 스터디
(3) 먼저 수행한 (1),(2)의 스터디를 통해 발견한 시스템의 한계점에 대한 개선 및 검증
(결과)
뉴스 초보자와 전문가 모두에게 News Kaleidoscope는 news coverage의 다양성을 분석하는데 효과적이고 task-driven한 워크플로를 지원했다.
저널리즘 전문 지식은 사용자의 인사이트나 시사점에 많은 상당한 영향을 미친다.
(의의)
News KIaleidoscope의 개발/검증에 대한 인사이트는 NLP를 활용해 뉴스의 coverage diversity를 분석하는 미래의 툴에 도움을 줄 수 있을 것이다.

1. INTRODUCTION
■ 이 논문의 주요 기여 내용
(1) 저널리즘과 미디어 연구에서 문제를 구성하는 Coverage diversity를 시각적으로 분석하기 위한 요구사항 파악
(2) Coverage diversity의 맥락에서 관심있는 사건에 대한 뉴스 기사를 분석하기 위한 새로운 시각화 시스템인 News Kalidoscope을 설계 및 구현
(3) 뉴스 전문가와 초보자 모두를 대상으로 한 일련의 강력한 평가를 바탕으로, 시각화와 NLP를 사용하여 Coverage diversity를 분석하기 위한 design guideline 및 시사점(implications) 전달
2. RELATED WORK
■ Bias and Framing in News Reporting
-
■ Visualizing News Reporting and Text Data
-
■ Contextualizing News Kaleidoscope to PreviousWork
-
-
3. Design Requirements Analysis
- Coverage diversity를 조사하기 위한 a visual analytics design(시각적 분석 설계) 에 동기를 부여하기 위하여, 뉴스 전문가 (저널리즘 교수) 세 명을 인터뷰 했다.
■ Significant problem in the journalism community
-> (1) 뉴스 기반의 보고(news-based reporting)에서 다양한 주제와 스타일을 분석하기 위한 computational tools 또는 visualization software가 부족하다.
-> (2) text data를 분석하기 위해 NLP algorithms와 같은 computational processes가 존재한 다는 것은 알지만, 이러한 기술적 요소에 대한 지식이 거의 없다.
■ 위와 같은 문제점을 바탕으로 도출한 다섯 가지 디자인 요구사항 (5 Design Requirements)
- 특히 news의 coverage diversity를 reporting하기 위한 맥락에서.
DR1: Retrieve articles about an event of interest.
(관심있는 사건에 대한 기사를 검색한다.)
- 인터뷰 참가자들의 분석 워크플로우 첫 단계는 관심있는 토픽에 대한 뉴스를 검색하는 것이다.
- 검색엔진에서 keyword-based 쿼리를 사용한다.
- 검색된 기사(retrieved articles)의 텍스트를 스키밍하거나 읽는다.
- 이것은 기존의 도큐먼트 시각화 시스템과 대조적인데, 기존 방식은 주로 전체 콜렉션에 대하여 집계된 내용을 보여주는 것(aggregate view)으로 시작했다.
- Summary view는 생략하고, 대신 사용자가 직접 high-level keywords 및 다른 제반사항(date, source, etc.)를 검색할 수 있도록 했다.
- Since such a summarization perspective is extraneous for the current domain (i.e., the participants already know what topic they want to search for, and what its high-level keywords are),
이러한 요약 관점은 현재 도메인에서는 불필요하다. (즉, 참가자는 이미 검색하려는 주제와 상위 키워드가 무엇인지 알고있다.)
DR2: Provide a high-level overview of coverage diversity.
(Coverage diversity에 대한 고수준의 overview를 제공한다.)
- 인터뷰 참여자들은 보통 검색된 목록의 기사들을 반복해서 읽는데, 이는 쉽게 지치게 한다. (which could quickly become overwhelming.)
- 검색된 기사의 overview를 제공하는 것은 관련 내용의 coverage diversity를 캣치하는데 도움이 된다.
- The participants described that providing an overview of the retrieved articles about the news event of interest, in a way that emphasises the general (i.e., high-level) trends or groupings of the coverage diversity, would provide an initial sense of the event’s coverage diversity.
- Such a view would also function to drive subsequent analysis, via an overview-plus-details workflow [44].
이러한 뷰는 overview-plus-details 워크플로를 통해 후속 분석을 이끌어내는 기능을 한다.
DR3. Select subsets of articles to analyze coverage diversity polarities.
(기사의 하위 집합을 선택하여 보도 다양성의 양극성(polarities)을 분석한다.)
- 참가자들은, 사건의 coverage diversity에 대한 high-level overview 뿐만 아니라, 뉴스 보도에서 흥미로운 편향성이나 의미를 담고 있는 기사들의 하위집합, 보도에서의 특정 극성을 조사하고 싶은 니즈가 있다고 했다.
- 이러한 양극성(polarities)의 second-level keywords를 분석하는것 뿐만 아니라, polarity-specific한 감정적인 미디어의 편향(emotional media biases) 또한 분석함으로써 뉴스 이벤트에 대한 coverage diversity의 뉘앙스적인(미묘한) 이해를 얻을 수 있다.
- 참가자들은 이러한 분석이 기사 하위집합 내부 및 전체에 걸쳐 비교할 수 있기를 원한다.
DR4: Provide data-level explanations to ensure trust and verification.
(신뢰와 검증을 보장하기 위해 데이터 수준의 설명을 제공한다.)
- non-expert users를 위하여 NLP 또는 데이터 마이닝 프로세스에서 모델과 알고리즘에 대한 신뢰와 해석가능성을 제공하는 것이 좋다.
- 뉴스기사의 클러스터링에 대해 논의할 때, 참가자들은 왜 기사들이 특정 방식으로 분류되었는지 이유를 알고 싶어했다.
- 따라서 고급 계산 기법이나 모델을 사용할 때는 모델 추천 및 결정에 대한 신뢰와 해석 가능성을 높이기 위한 메커니즘을 사용해야 함.
DR5: Visualization complexity should account for user expertise.
(시각화의 복잡성은 사용자의 전문성을 고려해야 합니다.)
- 대부분의 저널리즘 연구자들과 마찬가지로 참가자들은 고급 시각화 인터페이스에 대한 전문가가 아니었습니다. 즉, 지나치게 복잡하거나 난해한(esoteric) 시각적 디자인은 정보를 간결하고(succinctly) 쉽게 전달하는 데 실패할 수 있습니다.
- 대신, 인터페이스 디자인은 충분한 분석 기능을 제공하는 동시에 접근하기 쉽고 직관적으로 사용할 수 있도록 균형을 맞춰야 한다.
4. The News Kaleidoscope System Design
■ Full stack application -> Three primary facets:
(1) a data processing step
(2) a backend server for data storage, query, and NLP-based computation
(3) a frontend interface for visualization and interaction
4.1 Data Corpus and Preprocessing
■ Dataset: All the News
- 143,000 articles published on 14 news sites from 2015-2017
- the article text and related metadata (title, news site name, author, publication date, article URL, etc)
- across a spectrum of perceived liberal-to-conservative political biases.
■ 3 heuristic as pre-processing steps
(1) keyword identification
- Gensim NLTK library.
(2) named entity recognition
- Stanford NER library (named persons, locations, and organizations)
- keyword와 entities의 차이
- 둘은 가끔 중복되는 단어가 있지만, 의미적인 차이가 있다.
- keyword: Keywords give a broad sense of the topical content of an article, but the individual words are unclassified.
- In contrast, entities are specifically binned into classes, providing the user with an explicit set of relevant, descriptive proper nouns.
(3) emotional style (of each article)
- Plutchik's discrete categorical model 사용하여 emotional states를 8개의 primary emotions로 분류하고,
- 다음과 같은 쌍(pair)으로 조직했다.
: anger-fear, anticipation-surprise, joy-sadness, trust-disgust
- NRC lexicon (based on Plutchik's model) 을 이용해 기사 내의 emotional words를 분류했다.
- 이 후 각 단어들의 frequency를 계산하였다.
- 각 기사의 텍스트를 1x8의 vector로 표현하여 각 컬럼 e1 - e8은 n_i/N 을 뜻하고, n_i의 경우 특정 감정에 대한 단어의 개수이다. N은 전체 단어의 개수. (stop-word 삭제 이후)
4.2 Backend Server
■ Keyword Distance
-
■ Entity Distance
-
■ Temporal Distance
-
■ Aggregate Pairwise Distance
-
■ Clustering Articles by Emotional Style
-
4.3 Frontend Interface
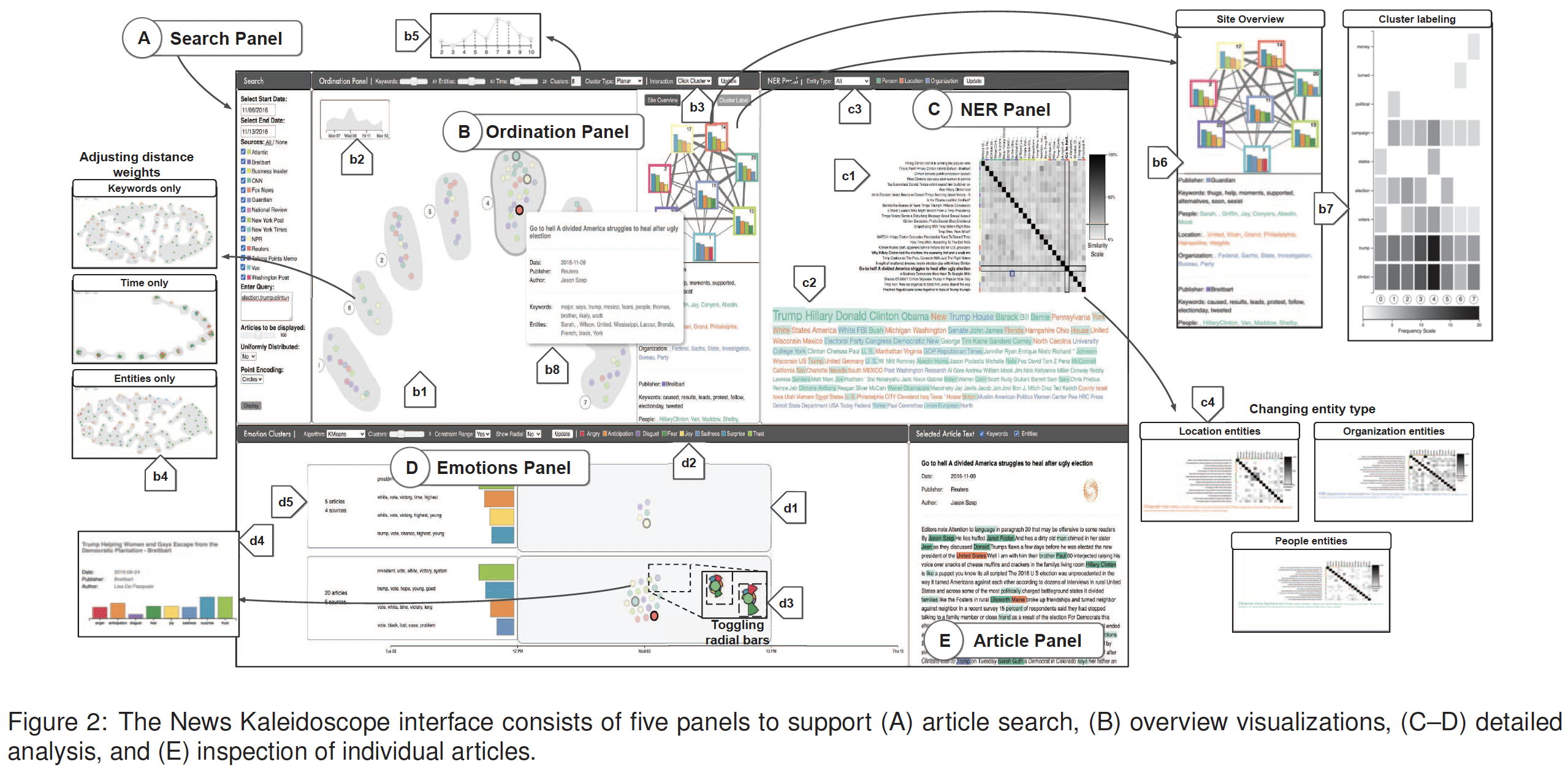
- 5개의 linked panels (A-E) 로 구성됨.
- Section 3에서 언급된 6개의 Task를 지원하도록 디자인됨.
(A) Search Panel
- 해당하는 Design Requirement: (DR1) keyword-baed search 로 뉴스이벤트에 대한 기사를 검색
- 사용자는 date ranges, news sites, keywords, article 갯수 에 대한 constraints/filters를 설정.
(B) Ordination Panel
- 해당하는 Design Requirement: (DR2) 검색된 기사의 overview를 제공한다.
- (b1) 뉴스 기사 하나가 하나의 circle (데이터 포인트)로 표현됨.
- 각 Circles는 k-means clustering을 써서 클러스터링됨.
cluster hulls rendered using bubble sets.
- (b2) 왼쪽 상단의 area chart. - 검색된 기사드의 temporal distribution을 보여줌.
- (b3) 상단의 디스플레이 세팅 위젯들
=> cluster computation에 대한 distance metric
=> k value (클러스터 개수)
=>scaling weights for the aggregate pairwise distances (w_k, w_e, w_t)
- (b4) Adjusting distance weights
- Keywords only, Time only, Entities only
- MDS plot
- (b5) k value에 hovering하면, silhouette score를 보여주는 툴팁 나타남.
(사용자의 k에 대한 선택을 돕기 위하여.)
- (b6) Site overview - 검색된 뉴스들의 뉴스 사이트 그래프
- 각 사이트의 보도 내용에 대하여 top-4 emotions(d2)을 bar chart로 표현했다.
이 chart를 통해 각 사이트가 현재 이슈에 대해 보도하는 내용을 summary-level로 비교할 수 있게 한다. 이 탭 하단에는 각 사이트의 주요 keywords와 entities를 보여준다.
- (b7) Cluster labeling - heatmap 을 활용하여, 각 클러스터의 top keywords를 보여준다.
- (b8) 각 article에 hovering하면 툴팁을 띄운다.
- 해당하는 Design Requirement: (DR3) 에 해당 - overview에서 기사의 하위그룹을 선택
- 올가미를 그리면 자유 형식의 선택이 이루어지며, 클러스터를 클릭하면 해당 클러스터의 모든 문서가 선택됨.
- 문서 하위 선택이 이루어지면 자세한 분석을 위해 NER 및 감정 패널이 채워짐.
(C) NER Panel
- (c1) adjacency matrix -> 두 article 간의 pairwise article similarities (entity distance metric을 기반으로 계산) (내 생각->왠지 기사 카피한 건지 검증용으로 유용할 것 같다.)
- (c2) word cloud -> 기사 subset에서 가장 많이 사용되는 엔티티를 빈도순으로 보여줌. 엔티티 유형별로 색상이 지정(Person: Green, location: Orange, Organization: Blue)
- (c1) adjacency matrix의 셀을 마우스로 가리키면 워드 클라우드에서 공유되는 엔티티가 강조 표시됩니다.
- (c3) 사용자는 어느 named entity types을 사용해서 similarity를 계산할 지 선택할 수 있다. (persons, locations, organizations or all)
(Location entities, Organization entities, People entities)
- (c4) Changing entity type : 키워드 대신, entity distance를 사용하여 추출된 기사 텍스트를 명시적인 카테고리로 분류한다.
(D) Emotions Panel
- article subselection의 emotional styles를 시각화 한다.
- 기사들은 emotional style vectors를 이용해 k-means clustering으로 클러스터링된다.
- (d1) 각 클러스터의 기사들은 임시로 출판일자 (publication day)로 정렬된다.
- (d2) panel의 control widget을 이용해, 클러스터 설정을 업데이트하고,
- (d3) article circles를 radial bar charts로 표현되도록 할 수 있다. (circle 자체가 토글 버튼처럼 동작)
- 각 기사의 emotional style vectors가 원 주위의 8개의 방사형 막대 집합으로 표시됩니다.
- (d4) 문서에 마우스오버하면 (표준) 막대 차트를 사용하여 이 벡터가 표시됩니다.
- (d5) 각 클러스터의 왼쪽에는 해당 클러스터의 상위 4개 지배적인 감정(및 각 감정에 가장 많이 기여하는 단어)이 표시되어 클러스터의 전반적인 특성을 한 눈에 파악할 수 있습니다.
(E) Article Panel
- article circle을 클릭하여, 또는 NER panel의 adjacency matrix title 을 클릭하여 개별 기사를 볼 수 있다. - (DR5)에 해당됨.
- Article panel에는 원본 기사의 텍스트와 메타데이터(author, news site, publication date)을 보여준다.
- 사용자는 기사 텍스트에서 추출된 키워드와 엔티티를 강조 표시할 수 있습니다.
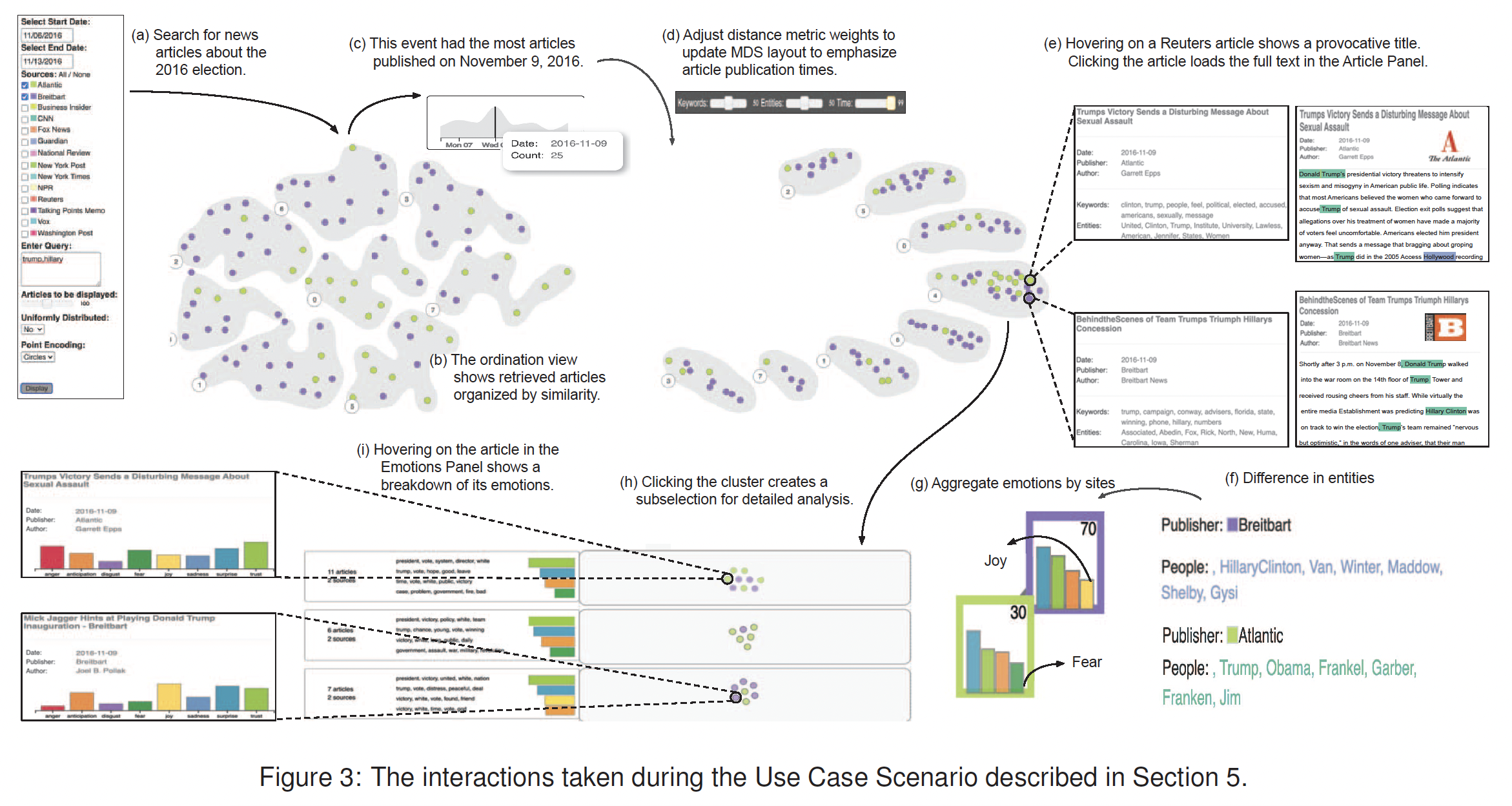
5. Use Case Scenario
6. Evaluation
6.1 Study #1 Design
■ Study Procedure
-
■ Participants
-
6.2 Study #1 Results
■ News Kaleidoscope supports scalable analysis of news events
-
-
■ The visual analytics were a novel experience
-
-
■ An unexpected usage of News Kaleidoscope as a validation system
-
-
■ Targeted suggestions by news experts
-
-
6.3 Study #2 Design
■ Training Stage
-
-
■ Exploration Stage
-
-
■ Review Stage
-
-
■ Participant Recruitment and Apparatus
-
-
6.4 Study #2 Results
-
6.4.1 System Ratings via Questionnaire Responses
설명
설명
6.4.2 Supporting Insights for Novice Users
■ For news novices, the interface was both easy to use and too complex.
설명
■ Aspects of the user experience echoed news experts.
설명
■ Clustering is effective for showing coverage diversity
설명
■ Participants recognized diversity, but it was hard to translate these into broader conclusions about media bias.
설명
6.5 Study #3
설명
7. Discussion
■ Novice news users recognize diversity, news experts can see research possibilities.
-
■ Explainability on demand improves sensemaking.
-
■ The need for visualization tools in journalism research.
-
■ Explicitly labeling bias in news stories?
-
■ Alternate visual encodings for News Kaleidoscope
-
7. CONCLUSION
- 중요한 결론 -
- 이론적 함의 -
- 실재적 함의 (practical implications) -
- Future work
- (1)
- (2)
나의 의견
논문을 선택한 이유
(1) 진행 중인 연구와 주제 면에서 비슷한 점이 많아서 관련 선행연구로 읽어보게 되었다.
읽고 난 후 의견
- 간단한 NLP 기술을 썼지만 시각적으로 구현했다는 점에서 실제 사용할 유저들에게 직관적으로 정보를 전달할 수 있다는 것이 이 시스템의 장점이라 생각된다.
- 저널리즘 관련 전문가 (관련 분야 교수 3인)을 인터뷰 하고 Design Requirements를 선정한 것이 인상 깊으며, 이 것을 바탕으로 후속 연구의 방향을 잡아도 괜찮을 것 같다.



