Language Models의 오래된 챌린지인 'long-term dependency(장기 의존성 문제)'와 context fragmentation 문제를 해결하기 위한 방법으로 제안된 Transformer-XL 모델에 대한 논문입니다. (XL => Extra Long)
Transformer-XL 모델은,
(1) Segment-level recurrence mechanism (세그먼트 수준의 재귀 메커니즘)
(2) Positional encoding scheme (포지션 인코딩 체계)를 활용하여 위의 문제를 해결합니다.
읽은 날짜 2023.04.04
카테고리 #자연어처리논문리뷰, #NLP, #LongerTexts
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- Authors: Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
- DOI: https://arxiv.org/abs/1901.02860
- Keywords: -
- Issue Date: Jun. 2019
- Publisher: ACL (Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics)
ABSTRACT
배경: Transformer는 long-term dependency를 학습할 수 있지만, 언어 모델링 셋팅에서 fixed-length context를 갖게 된다는 한계점이 있다.
목표: 'Transformer-XL' 이라는 뉴럴 아키텍처를 도입하여, 시간적인 일관성을 해치지 않으면서 fixed-length에서 오는 learning dependency를 가능하도록 한다.
방법:
(1)segment-level recurrence mechanism (세그먼트 수준의 재귀 메커니즘)
(2) positional encoding scheme (포지션 인코딩 체계)
(1), (2)로 구성된 Transformer-XL 아키텍처를 통해 longer-term dependency 문제와 context fragmentation 문제를 해결한다.
결과:
- longer-term dependency 학습:
Transformer-XL은 RNNs보다 80%, vanilla Transformer보다 450% 더 긴 dependency를 학습하고,
short/long sequences에서 vanilla Transformer보다 1800배 이상 빠른 퍼포먼스를 보였다.
[NLP 논문 리뷰 순서]
등장 배경, 이론적 기반, 기존 연구와의 차별점, 사용한 데이터, 모델/방법론, 실험 세팅, 실험 결과, 결과 분석, 이 논문에 대한 내 생각
1. 등장 배경
■ Long-range context dependency 문제
전통적으로 '언어'의 경우, sequential 한 데이터로 생각되었고
sequential data에서의 long-term dependency를 반영해 줄 수 있는 방법에 대해 연구자들이 노력해 왔다.
LSTM(Long Short-Term Memory)
> Hochreiter and Schmidhuber (1997) "Long Short-Term Memory"
- cell state vector와 gate 구조를 추가하여 이 문제를 어느 정도 해결하였지만,
- 모델 파라미터가 많아서 계산이 오래 걸리는 문제가 있으며,
- LSTM은 평균적으로 200개의 단어(step) 정도를 참고하여 문맥을 파악(context words)하므로,
- 여전히 많이 긴 길이의 데이터에 대해서는 기억을 하지 못하는 문제점이 남아 있다.
Transformer와 Attention
> Bahdanau et al.(2014) "Neural machine translation by jointly learning to align and translate."
> Vaswani et al. (2017) "Attention is all you need."
- attention 메커니즘을 활용하여 long-term dependency를 학습하고, 성능도 개선되었다.
- Vanilla Transformer의 경우, 처리 가능한 크기(segment)로 (naive 하게) 데이터를 split 해서 사용하게 된다.
■ Context fragmentation 문제
Vanilla Transformer의 segment 문제
- 인풋으로 사용되는 segment 내부의 character들 간의 dependency는 학습이 가능하지만
- segment 간의 dependency는 학습하지 못하게 된다.
- 즉, long-term dependency 문제 해결에 한계가 있다.
Character-level language modeling
> Al-Rfou et al. (2018) "Character-Level Language Modeling with Deeper Self-Attention"
- Transformer를 활용하여 character-level language modeling을 수행한 연구로, 결과적으로 LSTM보다 좋은 성능을 보였다.
- 하지만 이 연구에서도 Vanilla Transformer를 활용했기 때문에,
fixed-lengthdml segment 각각을 대상으로 학습을 진행했고, segment 간의 dependency는 학습하지 못하였다.
- 이 과정에서 segment는 문장의 구분, 의미적 구분없이 단순하게 character개수 기준으로 분리된 것으로,
segment 간의 dependency가 있는 경우가 많기 때문에 contextual information 부족 문제 및 성능에도 안 좋은 영향을 미침.
=> Context fragmentation 문제
■ 이 논문에서는
Transformer-XL 이라는 모델을 제안한다.
- 이 모델은 segment들 간의 long-term dependency를 모델링하고,
- 이를 통해 Context fragmentation 문제를 해결한다.
Transformer-XL은 word-level 및 character-level language modeling을 포함한 5개의 데이터셋에서 좋은 결과를 얻었다.
또한, Transformer-XL은 1억 개의 토큰으로만 학습된 수천 개의 토큰으로 비교적 일관된 긴 텍스트 기사를 생성할 수 있다.
■ 이 논문의 기술적 contributions(기여)
(1) introducing the notion of recurrence in a purely self-attentive model (순수 self-attentive model의 재귀 메커니즘)
(2) deriving a novel positional encoding scheme (포지션 인코딩 체계)
2. 이론적 기반
■ Language Modeling and Positional Embedding
(1) (AL-Rfou et al., 2018) Character-Level Language Modeling with Depper Self-Attention
-
> Rami Al-Rfou, Dokook Choe, Noah Constant, Mandy Guo, Llion Jones (2018)
> "Character-Level Language Modeling with Deeper Self-Attention"
> https://arxiv.org/abs/1808.04444
(2) (Shaw et al., 2018) Self-Attention with Relative Position Representations
- self-attention 개념을 그래프로 표현
> Peter Shaw, Jakob Uszkoreit, Ashish Vaswani (2018)
> "Self-Attention with Relative Position Representations"
> https://arxiv.org/abs/1803.02155
3. 기존 연구와의 차별점 및 모델 설명


■ 기존 연구 (Vanilla Transformer, self-attention)
Fixed-length segment 문제
- 핵심 문제: 임의로 긴 context를 fixed-size로 효과적으로 표현하도록 인코딩하는 방법
- 무한한 메모리와 연산능력이 주어진다면, entire context sequence를 unconditional Transformer decoder로 처리
(feed-forward neural network와 비슷) 하지만, 실제로는 리소스 제한 있음.
(naive 한) Segment split
- 실질적인 해결 방법 (One feasible but crude approximation)
- 전체 corpus를 관리 가능한 짧은 segments들로 자르고, 이전 segment에서의 contextual information은 무시한 채로
각 segment 내에서만 학습한다.
- (AI-Rfou et all, 2018) 연구에서 사용한 방법
Fixed-length segment 및 segment chunk로 인한 Context fragment 문제
(1) the largest possible dependency length(최대 종속성 길이)는
character-level language modeling에서 수백 개에 달하는 세그먼트 길이에 의해 상한이 정해짐. (AI-Rfou et all, 2018)
- self-attention 메커니즘은 RNN에 비해 vanishing gradient problem의 영향을 덜 받지만, vanilla model에서는 이런 최적화 이점을 충분히 활용하지 못함.
(2)
- 문장이나 다른 의미적 경계를 존중하기 위해 패딩을 사용할 수도 있지만, 실제로는 효율성 향상을 위해 긴 텍스트를 단순히 fixed-length의 segment로 자르는(chunk) 것이 일반적인 관행이다. (Peters et al., 2018; Devlin et al., 2018; Al-Rfou et al., 2018).
- 그러나 시퀀스를 단순히 고정 길이 세그먼트로 chunk 하면 Context fragmentation problem 발생한다.
Evaluation (평가, 예측 prediction) 때의 문제점
- Evaluation 동안 각 단계에서 vanilla model은 학습 때와 동일한 길이의 segment를 입력으로 사용
- Prediction 단계에서 각 segment의 맨 마지막 하나의 token만 예측하게 됨.
- segment는 한 step 오른쪽 이동하여 다시 동일한 과정 수행
- 이 과정에서 이전에 연산했던 token의 정보가 유지되지 않으므로, 매번 segment가 한 칸 이동할 때마다 이전에 계산했던 token도 다시 계산하게 되어 연산량이 많아진다. (비용이 많이 든다.)
■ 이 연구 (Transformer-XL 모델)
Segment-Level Recurrence with State Reuse
- 과거의 정보를 유지함으로써 long-term dependency를 해결하고 context fragmentation 문제를 회피한다.
- fixed-length로 인한 contextual information의 한계를 극복하고자 Recurrence mechanism 도입
- 학습 과정에서 기존 segment의 hidden state를 fixed 하고, 캐시에 저장(cashed)한다.
- step이 진행됨에 따라 기존의 hidden state를 참조하여 새로운 segment 처리할 때 재사용하여 context 정보를 확장(extend)한다.
- segment의 max input 개수만큼, 현재 시점에서 다음 예측에 참고할 수 있게 된다.
- segment단위의 recurrence(재귀)를 만들어서, context가 segment 간에 전달될 수 있게 된다.
- 장점: Evaluation(예측, prediction)시 속도가 빠르다.
메모리가 허용하는 한 최대한 많은 이전 시점들의 정보를 cache 할 수 있다.
- (학습 과정에서 hidden state sequence 계산 과정 수식은 생략했음.)
Relative Positional Encodings
- Transformer에 위와 같은 segment-level recurrence mechanism을 적용하게 되어, hidden state가 각각 몇 번째 순서에서 나온 정보인지 구분, 확인할 수 없다.
- 참고) 기존 Transformer의 경우, Absolute positional encoding사용.
이 경우, segment 순서와는 무관한 특정 길이 (L) 내의 segment 내의 순서정보로 positional encoding을 함.
Word embedding 벡터에 positional encodign 벡터를 더한 후 query, key 벡터 구하는 방식
- Transformer-XL의 경우, segment를 구반할 수 있는 position 정보가 필요하다.
그리고 동일 segment 내에서, 두 segment 간의 차이 (상대적 거리)도 알 수 있어야 한다.
- 제안 방법 => Injecting the relative distance dynamically into the attention score.
- (관련 수식은 생략했음.)
4. 사용한 데이터 및 실험 세팅, 실험 결과
■ Main Study 5가지 + Ablation Study로 진행
Main Study: 각 데이터셋 별로 실험 진행
Ablation Study: 모델의 feature를 하나씩 제거해 보며 성능을 파악
Main Study
실험을 위하여 총 5개의 데이터셋을 사용하였다.
실험 1) WikiText-103
○ word-level language modeling 실험
○ 데이터셋: WikiText-103
- 28K 기사로 구성된 103M training token, 기사당 3.6K token으로 구성
- Attention length (training 384, evaluation 1600)
-> (Merity et al.,2016)
○ 목적: long-term dependency 측정 (long-term dependency를 잘 처리하는가?)
○ 평가 Metric: PPL(Perplexity)
○ 결과: (Table 1) Standard, Large 모델 모두 큰 성능 증가를 보임.

실험 2) enwik8
○ character-level language modeling 실험
○ 데이터셋: enwik8
- unprocessed Wikipedia text 100M bytes, 모델 크기 제한
-> (LLC, 2009)
○ 평가 Metric : BPC (Bits-Per-Character) (문자를 인코딩하는데 필요한 평균 비트수의 양, 낮을수록 좋다.)
○ 결과: (Table2) 선행 연구인 AI-Rfow et al., (2018)의 모델보다 훨씬 좋은 성능을 보임.

실험 3) text8
○ character-level language modeling 실험
○ 데이터셋: text8
- processed Wikipedia characters (소문자, a-z 외 제거), Enwik8과 유사
> (LLC, 2009)
○ 목적: enwik8과 동일한 실험 진행
○ 결과: 좋음

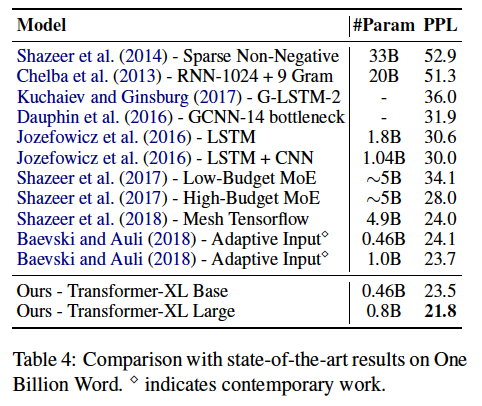
실험 4) One Billion Word
○ word-level language modeling 실험
○ 데이터셋: One Billion Word
- 문장끼리 shuffling 되어 있어서, long-term dependency보다는 short-term dependency를 확인하기 위한 모델.
-> (Chelba et al., 2013)
○ 결과: 좋음
실험 5) Penn Treebank
○ word-level language modeling 실험
○ 데이터셋: Penn Treebank
- 1M training token (비교적 작은 데이터셋으로 small-sized DB 동작 확인)
> (Mikolov and Zweig, 2012)
○ variational dropout과 weight average를 적용
○ 결과: 데이터셋이 작더라도 Transformer-XL 성능 좋음.

Ablation Study
(1) encoding 방법에 따른 비교
각 다른 encoding 방법을 사용한 모델을 이용해 실험
- Transformer-XL의 Relative encoding
- Shaw et al.(2018) => Relative encoding
- Vaswani et al. (2017) => Absolute encoding
- Al-Rfouet al. (2018) => Absolute encoding
결과: Transformer-XL이 가장 성능이 좋으므로, Recurrence와 relative encoding을 사용하는 것이 좋다는 결론
(2) Recurrence mechanism의 효과 확인
longer context dependency 필요 없는 데이터셋으로 실험했을 때에도
recurrence mechanism을 사용하는 것이 context fragmentation에 효과적임을 입증했다.
5. CONCLUSION
Transformer-XL 모델을 제안한다.
이 모델의 아키텍처에서 아래와 같은 방법을 사용하여,
(1) segment-level recurrence mechanism (세그먼트 수준의 재귀 메커니즘)
(2) positional encoding scheme (포지션 인코딩 체계)
기존의 자연어 처리의 이슈였던 longer-term dependency 문제와 context fragmentation 문제를 어느정도 해소할 수 있다.
Transformer-XL 모델은 성능면에서 기존의 State-of-the-art 모델보다 우수한 실험결과를 얻었다.
나의 의견
논문을 선택한 이유
(1) XL-Net의 베이스가 되는 연구라고 하여, 읽어보게 되었다.
(XL-Net 논문을 보면, Transformer-XL을 backbone neural architecture이라 말하며, 연구의 baseline으로 설정한다.)
읽고 난 후 의견
- 아직 주요 NLP 논문들을 읽어보지 않은 채로, 어쩌다 보니 이 논문부터 읽어보게 되었다.
이전에는 그냥 주요 개념만 인터넷을 통해 습득하면 되는 게 아닐까 했는데,
이번을 기회로 논문을 읽는 것이 관련 연구들에 대한 전체적인 흐름과 방향을 보고 이해하는데 도움이 된다는 것을 알게 되었다. - segment 간의 recurrence작업을 하는 것은 간단하지만 이것을 실제로 동작하도록 구현하고, 실험까지 마치는 것은 까다로운 작업일 것이라고 생각된다.
- GPT 4와 같은 LLM이 유행인 상황에서, 소프트웨어적인 알고리즘의 한계는 어느정도 하드웨어로 해결가능한 상황인 것 같다. 하지만 모두가 좋은 하드웨어를 가질 수 없으니 소프트웨어적으로 최적화된 방법으로 문제를 해결하는 것은 좋다고 생각한다. 앞으로 AI가 경량화되면서 이런 비슷한 연구가 더 많이 나오지 않을까 싶기도 하다.
- ChatGPT 가 나오면서, 더 이상 이런 예전 연구를 읽는게 의미가 있을까? 하는 생각도 조금 들었다.
- 하지만 또 한편으로는 이 전의 논문들을 조금씩 접하고 이해하면서 어떻게 지금 Generative AI 까지 와서 GPT3, 4가 엄청난 성능을 보이게 됬는지 NLP 연구 및 발전의 큰 줄기의 흐름을 이해하고 싶다.



