기존의 Argument mining은 주로 tree구조였지만, 이 구조에서는 실생활의 복잡한 argument structure를 담을 수 없다는 한계가 있었으므로, self-attention 기반의 임베딩을 통해 link-prediction을 개선하는 방법론을 제안하는 논문입니다.
연구의 대상은 독백이 아닌 토론과 같은 담론 상황에서의 argument mining입니다.
읽은 날짜 2023.03.28
카테고리 #자연어처리논문리뷰, #ArgumentMining, #NLP, #Transformer
Argument Mining using BERT and Self-Attention based Embeddings
- Authors: Pranjal Srivastava, Pranav Bhatnagar, Anurag Goel
- DOI: https://doi.org/10.48550/arXiv.2302.13906
- Keywords: Argument Minting, Transformer, Self-Attention, BERT
- Issue Date: 2022
- Publisher: 2022 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N)
ABSTRACT
배경: Argument mining은 자연어 텍스트를 통해 전달하는 추론과 근거의 구조를 자동으로 식별하고 추출하는 작업이다. 이 분야의 대부분 SOTA(state-of-the-art) 작업들은 tree-like structure와 언어 모델링을 사용하는데 중점을 두었다.
문제점: tree-like structure 접근방식은 online forume이나 실생활에서의 복잡한 argumentation structure를 모델링할 수 없다.
목표: 온라인 담론에서 널리 퍼진 일반적인 논쟁 구조(argument structure)에서 인과적인 순서도(causational hierarchies)를 모델링한다.
방법: attention기반의 임베딩을 사용하여 모델의 link-prediction을 수행한다.
의의: Argument mining을 위한 새로운 방법론을 제안한다.
1. INTRODUCTION
■ Argument mining 연구 흐름: Tree구조에서, Tree구조가 아닌 방법으로.
Argument mining 연구 분야에서는 tree-like structure를 사용하여 argument들의 구조를 나타내는 것이 일반적이다.
tree를 파싱하는 것과 관련된 기술은 이미 많이 있었으나
실제 데이터의 argument는 이러한 방법에서 제시하는 이상적인 시스템과 맞지 않았다.
최근에는 tree기반이 아닌 방법으로 argument mining을 하는 방법들이 연구되고 있다.
■ NLP 연구 트렌드: 전이 학습(Transfer learning)
RNN, CNN, LSTM, Attention-based 메커니즘은 contextual한 정보를 활용할 수 있게 하며,
transformer-based 아키텍쳐들이 attention 매커니즘을 사용해 NLP관련 태스크 성능을 높여 SOTA를 기록하고 있다.
최근 트렌드는 거대한 데이터로 사전 학습한 pre-trained model에서 전이학습(Transfer learning)을 활용하여 태스크를 수행하는 것이다.
■ 이 연구에서는
Argument mining 작업에서 Transformer 기반 아키텍쳐를 적용한다.
(1) 데이터셋: Cornell eRulemaking Corpus: Consumer Debt Collection Practice(CDCP)
- 선행연구인 Ting Chen (2021) "BERT Argues: How Attention Informs Argument Mining" (Thesis) 과 동일한 데이터셋
(2) 모델링: BERT 언어 모델과 트랜스포머 인코더 레이어를 사용한다.
Argument components간의 계층적인 관계를 추출하기 위한 임베딩을 생성한다.
2. RELATED WORK
2-A. Argument Mining
■ Argument Mining 관련 연구들
(1) Moens et al. (2007)
법률 텍스트 모음에서 arguments를 분류(classify)하기 위해, n-grams, keywords, parts of speech(품사 구분) 등을 식별
> Moens, M.-F., Boiy, E., Palau, R.M., Reed, C. (2007)
> Automatic Detection of arguments in legal texts.
> Proceedings of the 11th International Conference on Artificial Intelligence and Law, pp. 225–230 (2007)
(2) Levy et al. (2014)
컨텍스트에 따른 claim detection을 위한 3단계 접근 방식에 대한 연구
> Levy, R., Bilu, Y., Hershcovich, D., Aharoni, E., Slonim, N. (2014)
> Context dependent claim detection.
> Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, pp. 1489–1500 (2014)
(3) Palau, R.M., Moens, M.-F. (2009)
corpora(말뭉치)에서 argument & relations 모델링하는 end-to-end approach
다음과 같은 3단계 파이프라인 제안:
◦- Argument detection,
◦- Argument proposition classification
◦- Detection of argumentation structure
수동으로 Context Free Grammar를 적용해 tree-like 구조의 argument relation structure 생성
> Palau, R.M., Moens, M.-F. (2009)
> Argumentation mining: the Detection, classification and structure of arguments in text.
> Proceedings of the 12th International Conference on Artificial Intelligence and Law, pp. 98107 (2009)
(4) Stab and Gurevych (2014)
Argument mining을 위한 3가지 주요 서브루틴 정의
◦- Component Identification (컴포넌트 식별)
◦- Component Classification (컴포넌트 분류)
◦- Argument Relation Prediction (Argument-relation 예측)
: arguments의 다른 부분들을 연결하고, 논리적인 종속성을 식별
> Stab, C., Gurevych, I. (2014)
> Annotating argument components and relations in persuasive essays.
> Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, pp. 1501–1510 (2014)
■ tree가 아닌 구조로 Argument Mining을 접근한 연구들
- tree구조는 온라인 포럼이나 토론 스레드 같은 실제 담론(discourse)의 복잡하고 다양한 그래프 구조를 고려하지 못함.
(1) Niculae et al. (2017)
non-tree argument mining 접근을 제안한 최초의 연구
SVM(Support Vector Machines)와 Bidirectional LSTM을 활용하여 factor graph model 접근법을 사용했다.
> Niculae, V., Park, J., Cardie, C.
> Argument mining with structured svms and rnns
> arXiv preprint arXiv:1704.06869 (2017)
(2) Galassiet al. (2018)
LSTM과 residual network connections를 탐색하여 argument 컴포넌트간의 link prediction에 집중했다.
> Galassi, A., Lippi, M., Torroni, P.
> Argumentative link prediction using residual networks and multi-objective learning.
> Proceedings of the 5th Workshop on Argument Mining, pp. 1–10 (2018)
(3) Morioet al. (2020)
Task-Specific Parameterization (TSP)을 활용하여 proposition 시퀸스를 인코딩하고,
Proposition-Level Biaffine Attention (PLBA)을 활용하여 향상된 edge prediction을 통해 non-tree argument를 예측하는 방식을 제안했다.
> Morio, G., Ozaki, H., Morishita, T., Koreeda, Y., Yanai, K.
> Towards better non-tree argument mining: Proposition-level biaffine parsing with task-specific parameterization.
> Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 3259–3266 (2020)
2-B. BERT
■ BERT 아키텍처 관련 연구
(1) <Attention is all you need>, Vaswani et al. (2017)
self-attention 메커니즘을 갖춘 transformer 아키텍처를 처음 제안한 논문
RNN의 메모리 및 처리 비용을 개선
> Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.
> Attention is all you need.
> Advances in neural information processing systems 30 (2017)
(2) <BERT>, Devlin et al. (2018)
BERT(Bidirectional Encoder Representations from Transformers) 모델을 소개한 논문.
라벨링 되지 않은 텍스트에서 pre-train된 deep bidirectional representations를 사용한다.
pre-trained된 모델은 하나의 추가 레이어에서 fine tuning되어, 다양한 범위의 문제에 사용될 모델을 생성할 수 있다.
> Devlin, J., Chang, M.-W., Lee, K., Toutanova, K.
> Bert: Pre-training of deep bidirectional transformers for language understanding.
> arXiv preprint arXiv:1810.04805 (2018)
■ BERT 를 기반으로 한 Argument mining 관련 연구
(3) Reimers et al. (2019)
BERT와 ELMo를 활용하여, open-domain argument search에서 토픽에 종속된 argument를 분류(classify)하고 clustering 한 연구
> Reimers, N., Schiller, B., Beck, T., Daxenberger, J., Stab, C., Gurevych, I.
> Classification and clustering of arguments with contextualized word embeddings.
> arXiv preprint arXiv:1906.09821 (2019)
(참고) <ELMo>, Peters et al. (2018)
ELMo (Embeddings from Language Models)
> Peters, M.E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., Zettlemoyer, L.
> Deep contextualized word representations (2018)
> https://arxiv.org/abs/1802.05365
(4) Chakrabarty et al. (2020)
Argument간의 관계 예측(relation prediction)에 대한 연구
기존의 argument 모델링 작업은 대부분 독백(monologues) 데이터를 활용했으나,
이 연구에서 사용한 데이터셋은 온라인 설득 포럼의 데이터셋이었다.
기존의 모델(BERT)를 fine-tuning하고, 수사적 구조 이론(Rhetorical Structure Theory)에 기반한 담화 관계를 활용하는 맥락에서
contextual information을 사용하여 관계를 예측함.
pointer networks와 pre-trained 언어 모델을 사용하는 최근의 SOTA 방법들에 비해 개선된 방법.
> Chakrabarty, T., Hidey, C., Muresan, S., McKeown, K., Hwang, A.
> Ampersand: Argument mining for persuasive online discussions.
> arXiv preprint arXiv:2004.14677 (2020)
(5) Ting Chen (2021)
Deep contextualized word embedding을 활용하여 non-tree argument mining을 시도하겠다는 컨셉.
DAG(Directed acyclic graph, 방향성 비순환 그래프)를 형성하는 arguments를 예측하기 위하여
pre-trained BERT기반의 모델과 Proposition Level Biaffine Attention, 그리고 Weighted Cross Entropy Loss를 활용하는
새로운 파이프라인을 제안하는 연구.
의의 : 계층 관계를 모델링 하기 위해 recurrence(반복)작업을 제안
Bert기반의 모델에서의 deep contextualized word embedding의 효과를 보여줌.
사용한 데이터셋: Cornell eRulemaking Corpus: Consumer Debt Collection Practice(CDCP)
> Chen, Ting,
> BERT Argues: How Attention Informs Argument Mining (Thesis)
> https://scholarship.richmond.edu/honors-theses/1589/
(참고) Cornell eRulemaking Corpus: Consumer Debt Collection Practice(CDCP)
- 이 데이터셋은 eRule-making 토론 포럼의 comments에 대한 argument annotations의 모음으로,
argument의 구조가 반드시 tree구조를 생성하지 않는다.
- 이 데이터셋은 현재(2023년 기준) the University of Richmond 교수인 Joonsuk Park 님의 2018년 논문인 <A Corpus of eRulemaking User Comments for Measuring Evaluability of Arguments> 에서 개발되었다.
- 바로 위의 선행연구를 찾아보니 Ting Chen님의 박사 논문이며, 지도교수님이 Joonsuk Park교수님이셨다.
- 논문 & 데이터셋 링크: Joonsuk.org (richmond.edu) 에서 논문 및 데이터셋 모두 구할 수 있다.
> A Corpus of eRulemaking User Comments for Measuring Evaluability of Arguments
> Joonsuk Park and Claire Cardie
> In Proceedings of the 11th Language Resources and Evaluation Conference (LREC). 2018.
3. PREREQUISITES
3-A. Problem Formulation
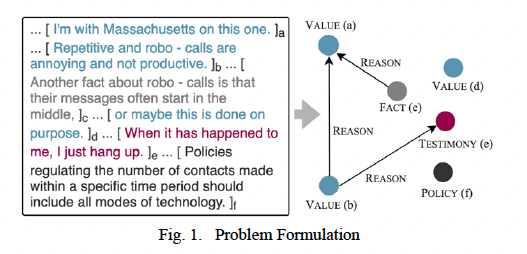
입력 데이터: 사용자가 argument에 대한 태그를 표기한 annotation(이 달린 텍스트
각 argument의 컴포넌트는 annotated text의 특정 범위(span)에 대응된다.
모델은 argument의 proposition(명제)에 대한 type과 다른 argument로 연결되는 edge를 포함한다.
3-B. Embeddings
고차원 벡터를 저차원 벡터로 변환해서 모델에 사용한다.
임베딩에서 의미상 유사한 입력을 함께 배치하여, semantic한 정보를 캡처할 수 있으며,
임베딩에서 얻은 인사이트는 모델에서 재사용 하여 다른 NLP 태스크에서 활용 가능.
3-C. Transformer
■ Transformer
RNN (Recurrebt Neural Networks) 에서 요구되는 많은 계산량과 메모리량에 대응하기 위해 나온 방법.
Transformer는 Multi-head self-attention방법을 사용하기 때문에, 모델을 사용한 병렬 학습이 가능하다.
■ 이 연구에서는
BERT를 이용해 argument components의 sentence level embeddings을 얻는다.
이 임베딩으로 argument component의 분류 작업 및 edge detection을 수행한다.
그리고 Transformer 의 Encoder layer에서 argument 문장의 context를 캡처하기 위한 인코딩을 얻는다.
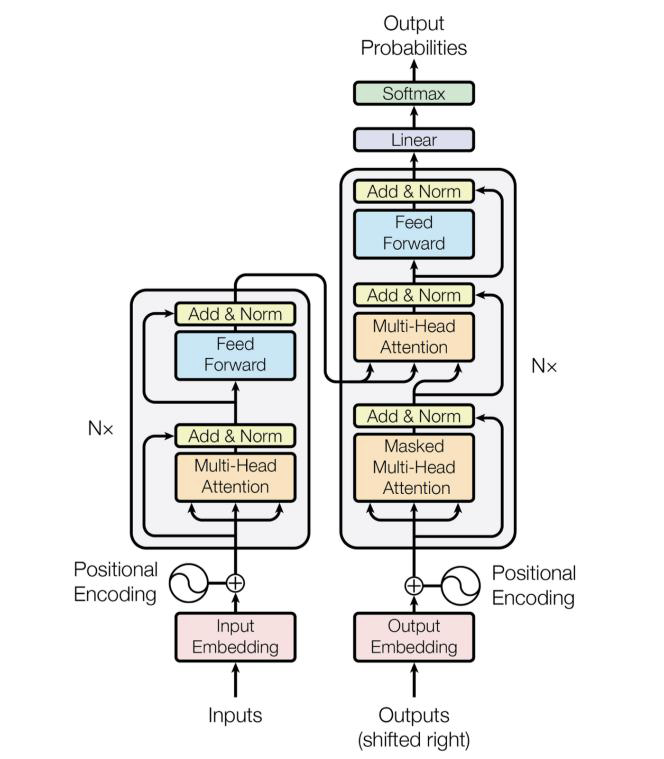
3-D. BERT
■ 이 연구에서는
Huggingface transformer 라이브러리에서 'bert-base-uncased' 모델을 사용했다.
■ BERT
BERT는 33억개(3.3billion)의 단어가 포함된 영어 말뭉치(corpus)에 대해 사전 학습한 모델로,
BERT는 12개의 transformer encoder layer가 쌓여있는 구조이다.
Transformer기반의 모델을 쓰는 것의 장점은, attention 메커니즘을 통해 병렬 연산이 가능하여, 효율적이라는 것.
(모델이 동시에 모든 단어를 보고, 그 중 태스크에 적합한 것을 선택할 수 있다.)
■ BERT의 훈련 방법: MLM 및 NSP
(1) Masked Language Modelling (MLM)
- 입력 문장의 15%를 랜덤 마스킹하여, 가려진 단어를 예측하도록 훈련
(2) Next Sentence Prediction (NSP)
- 두 개의 마스킹 된 문장이 서로 자연스럽게 이어지는지의 여부를 예측
4. PROPOSED APPROACH
■ The proposed approach is divided into two phases:
Phase I: Classification of argument components
Phase II: Edge detection on encodings
Phase I: Classification of argument components
■ BERT fine-tuning
BERT를 supervised-learning으로 CDCP corpus에 대해 fine-tuning하고,
BERT를 이용하여 argument spans를 argument components로 분류(classify)한다.
■ Embeddings
BERT는 임베딩의 모음을 생성하지만,
주로 임베딩의 첫번째 요소인 [CLS] 토큰의 임베딩을 이용해 sentence-level의 의미를 뽑아낸다.
그러므로, 이 연구에서도 [CLS] 토큰에 대한 최종 임베딩을 classifier의 입력으로 전달한다.
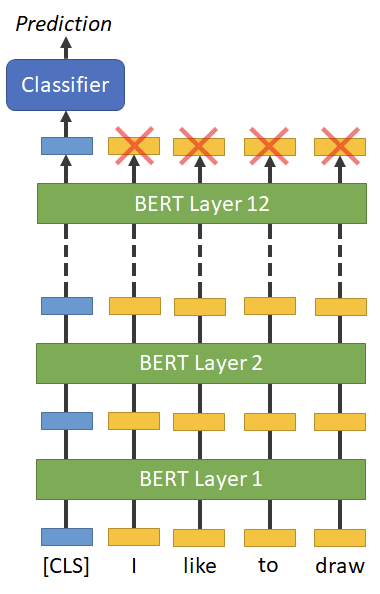
Hidden layers의 [CLS] 토큰을 pooling(풀링)하여 sentence-level 임베딩을 얻어, edge detection에 사용한다.
Phase II: Edge detection on encodings
■ 아이템
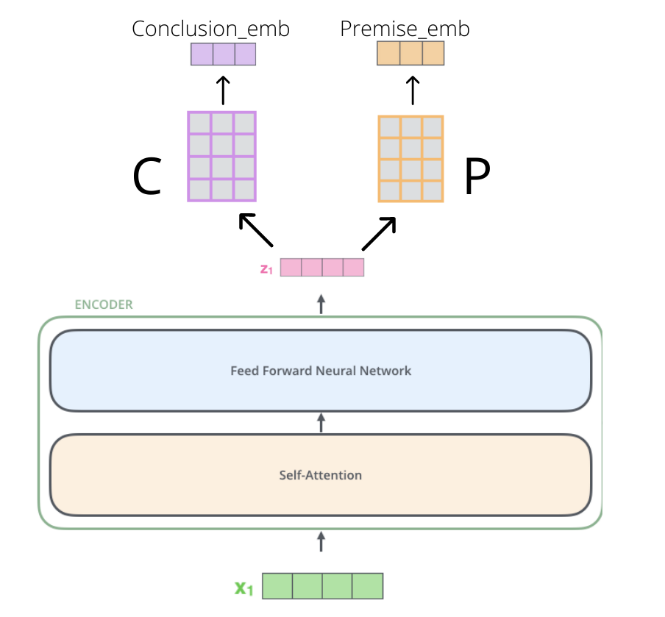
Hidden layers의 마지막 n layers에 가중 평균(weighted average)를 적용하여, 임베딩을 만든다.
■ 임베딩 수식
e_i : i번째 문장에 대한 sentence encoding
w_j : j번째 layer에 대한 weight
E_j = [Emb_1, ..., Emb_n] 으로, j번째 layer의 hidden output이다.
$$ \begin{align*} e_i = \sum_{j=1}^{n} {W_j*E_j} \end{align*} $$
위의 방식으로 생성한 임베딩을 transformer의 encoder layer로 전달하여 통과시킨다.
임베딩은 Conclusion과 Premise를 의미하는 C와 P space로 각각 투영된다.
(논문에 Conclusion과 Projection space라고 오타가 있었다!)
$$ Conclusion_{emb_i} = C * e_transformer_i $$ $$ Premise_{emb_j} = P * e_transformer_j $$ $$ Conclusion_{emb_i} * Premise_{emb_j} = \left\{\begin{matrix}1, (\text{if j is the premise, i is the conclusion}) \\0, (\text{if j is not the premise of i}) \end{matrix}\right. $$
5. EXPERIMENTATION AND RESULTS
5.1 Dataset Used
■ Cornell eRulemaking Corpus: Consumer Debt Collection Practice(CDCP)
Park and Cardie(2018) 에서 제안한 CDCP 데이터셋의 corpus(말뭉치)를 사용
이 corpus는 argument relations를 directed graph(방향 그래프)의 링크로 모델링했다.
데이터셋 내용:
- eRulemaking forum에서 나온 731개의 user comments 데이터
- 약 88,000개의 단어로 구성된 4500개 이상의 명제(propositions)로 구성
데이터셋의 명제(propositions)
(i) Value (45%): 구체적인 주장(claim)이나 제안이 없는, 가치 판단(value judgements)을 포함하는 명제
(ii) Policy (17%): 구체적인 행동 방향(direction of action)을 지시하는 명제
(iii) Reference (1%): 어떤 입장(position)을 뒷받침하기 위해 어떤 출처를 인용
(iV) Fact (16%): 객관적인 증거(evidence)를 통해 확인할 수 있는 주장(assertion)
(V) Testimony (21%): 저자의 경험적 지식에서 비롯된 객관적인 주장(proposition)
> A Corpus of eRulemaking User Comments for Measuring Evaluability of Arguments
> Joonsuk Park and Claire Cardie
> In Proceedings of the 11th Language Resources and Evaluation Conference (LREC). 2018.
5.2 Experimental Setup
■ 모델 학습
training, test 데이터셋을 각각 75%, 25% 로 구성
Argumentative propositions(논증 명제)의 span(범위)에 대한 분류(classification)을 위해, BERT 모델 학습 진행
3 epoch으로 Adam optimizer를 사용하여 학습
■ Edge detection
BERT classification 모델의 마지막 n=4 layers를 가중치 누적을 위해 사용함.
이 데이터는 BERT 출력 크기인 769*768 dimension의 transformer encoder layer를 통과 후,
100-feature 임베딩 스페이스로 투영된다. (각각 Conclusion embeddings와 Premise embeddings를 위하여)
100 epoch에 대하여 AdamW optimizer를 사용하여 링크 예측 모델을 학습
5.3 Results Analysis
■ F1 스코어 평가
분류(classification) 및 링크 예측(link prediction) 작업에 대한 F1 스코어 평가
*F1 스코어 = Precision과 Recall의 조화 평균(harmonic mean) 로, 수치가 높을수록 좋다.
*F1 스코어는 정밀한 링크 예측 작업의 불균형적인 특성을 고려할 때 적합한 지표이다.
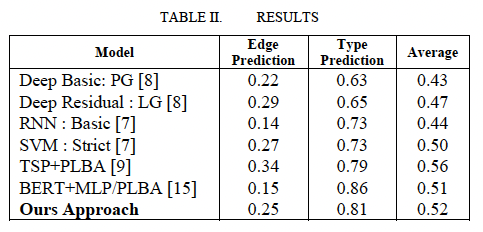
Results table을 보면,
- 이 연구에서 제안된 방식(Our Approach)가 다른 벤치마크보다 비슷하거나 우수한 성능을 보임을 알 수 있다.
- TSP+PLBA 방식의 Edge Prediction이 Our Approach보다 성능이 약간 높다.
*TSP: Task-Specific Parameterization
*PLBA: Proposition-Level Bi-Affine Attention
6. CONCLUSION
- 중요한 결론 - 이 연구에서 제안된 approach가 대부분의 baseline과 다른 접근방식보다 성능이 우수하다.
- 이론적 함의 - 온라인 담론(online discourse)의 argument structure에서 causational hierarchies(인과관계 계층)을 모델링하기 위한 attention-based approach를 제시한다.
나의 의견
논문을 선택한 이유
(1) 자연어 텍스트에서 Argument(논증)을 찾아낼 수 있는 방법을 찾다가, 작년에 나온 BERT기반의 연구가 있어서 읽어보게 되었다.
읽고 난 후 의견
- 선행 연구인 Ting Chen (2021)의 연구과 차별점은 무엇일지 궁금해하면서 읽었다.
- fine-tuning을 어떻게, 어떤 부분을 했는지, 그리고 데이터셋에서 arguments 는 어떤게 있고 edge detecting해서 나온 edge는 어떤게 있는지가 궁금했는데 관련 설명이 없어서 아쉬웠고, 논문의 내용이 연구에 대한 내용 보다는 Transformer나 BERT에 대한 컨셉 설명의 내용이 더 많은 듯하다.
- Conclusion에서 갑자기 causational hierarchies 라는 표현을 써서 당황스러웠다. 앞에 조금더 설명이 있으면 좋겠다.



