BERT에 input으로 image와 sentence의 쌍을 전달하여 Vision-and-language 관련 태스크를 테스트 한 ViLBERT (Vision-and-Language BERT)에 대한 연구 입니다.
읽은 날짜 2023.04.25
카테고리 #자연어처리논문리뷰, #Multimodal, #Vision_and_Language
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
- Authors: Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee
- DOI: https://arxiv.org/abs/1908.02265
- Keywords:
- Issue Date: Aug, 2019
- Publisher: NeurIPS 2019 (Neural Information Processing Systems, 신경정보처리시스템학회)
ABSTRACT
(목표) Vision-and-Language BERT를 의미하는 ViLBERT 모델을 제안한다.
(방법) VilBERT는 BERT 아키텍처를 multi-modal two stream model로 확장하여, Vision과 text 모두 인풋으로 처리하여 co-accentional transformer layers를 통해 상호작용한다.
평가: 대규모의 자동 수집 Conceptual Captions datasets에 대하여 모델을 사전 학습하고, 4가지 Vision-and-language Tasks 에 대한 태스크를 수행하는 것을 평가한다.
- 4가지 Vision-and-language Tasks
(1) Visual question answering
(2) Visual commonsense reasoning
(3) Referring expressions
(4) Caption-based image retrieval
(결과 및 의의) 4가지 Vision-and-language Tasks 에서 성능의 개선이 있었다.
이 연구는 vision과 language을 task training의 일부로써 학습하던 learning groundings에서 벗어나, 사전 학습을 통해 전이 가능한 visual grounding으로 다루는 것에 대한 작업의 전환을 보여준다. (잘 모르겠음. --> vision을 language로 전환하는 훈련을 따로 하는 것이 아니라, 멀티 모달로 함께 사전 학습할 수 있다는 뜻일까? )
1. 등장 배경
■ Vision-and-Language
- 자연어와 시각적인 부분을 함께 연결(접지, grounding)할 필요가 있다는 필요성
- 이미지나 비디오, full 3D 컨텍스트에서 자연어 응답이나 자연어 생성을 통해 시각적인 이해를 하고자 하는 접근 방식
- 문제점: pair를 이루고 있는 vision-linguistic data가 적거나 편향된 경우 제대로 generalize되지 않음. (myopic grounding)
■ pretrain-then-transfer 학습
- 사전 학습 후 전이 학습을 하는 접근 방식
- 대규모 데이터로 미리 학습된 모델을 가져와서 도메인에 맞게 활용할 수 있게 함.
■ 이 논문에서는
learning task에 구애받지 않고 공통적으로 이미지와 자연어의 표현에 함께 쓸 수 있는 모델을 개발한다.
visual grounding을 위해 사전 학습된 모델로, vision-language task에 범용으로 쓰일수 있게 한다.
2. 이론적 기반
■ Object detection
- 이미지에 있는 물체들을 판별해내는 과제
■ Naive approach
- VIdeoBERT에서 사용되었던 접근법으로,
- 비주얼 인풋 스페이스를 클러스터링을 통해 세분화하고, 비주얼 토큰을 텍스트 토큰과 똑같이 취급하여 사전학습된 BERT 모델에 인풋으로 사용한다.
■ Vision-and-Language Tasks
(1) VQA (Visual QA)
(2) VCR (Visual Commonsense Reasoning)
(3) Grounding Referring Expressions
(4) Caption-Based Image Retrieval
(5) ‘Zero-Shot’ Caption-Based Image Retrieval
3. 모델/방법론
■ 모델: ViLBERT (Vision-and-Language BERT)
- BERT 아키텍처를 멀티모달 two-stream 모델로 확장하여,
- visual과 textual 인풋을 별개의 분리된 스트림으로 처리하고,
- co-attentional 트랜스포머 레이어를 통해 상호 작용한다.
■ 방법론:
- (image, sentence)의 쌍을 BERT에 넣는다. (마치 sentence BERT와 비슷하다.)
- image의 경우, 사전 학습된 objection detection 모델을 사용하여 추출된 feature를 이미지 토큰으로 사용하여, 트랜스포머 인코더에 입력값으로 전달한다.

■ Objection detection network의 예
Faster R-CNN model, MAttNet 등.
■ Pre-training Tasks
(1) Masked multi-modal learning task
-이미지 입력의 15%를 마스킹하여, 모델이 해당 이미지 영역의 semantic classes를 예측
(2) Multi-modal alignment prediction task
-이미지와 텍스트가 잘 어울리는지 예측
4. 사용한 데이터 및 실험
■ 실험 세팅
- Baseline: Single-Stream, ViLBERT+ (without pre-training)
■ Data & Tasks
[Training]
- Conceptual Captions: 3.3M image-caption pairs
- Objection detection network: Faster R-CNN모델 사용
[Evaluation]

1) VQA (Vision QA) Task
- VQA 2.0 dataset: 1.1M questions, each with 10 answers
2) VCR (Visual Commonsense Reasoning) Task
- VCR dataset: 290K multiple choice problems from 110K movie scenes
- VQA + Rationale (answer justification)
3) Grounding Referring Expressions Task
- RefCOCO+ dataset
- object detection network: MAttNet
- 각 visual feature가 가지는 IoU (Interaction over Union) 를 측정
4) Caption-Based Image Retrieval Task
- Flicker30k dataset: 31K Flicker images with 5 captions each
- 이미지와 캡션 쌍의 데이터 스코어링
5) Zero-Shot Caption-Based Image Retrieval
- Flicker30k dataset: 31K Flicker images with 5 captions each
- caption-based Image Retrieval을 학습없이 적용
5. 결과
(1) SOTA 모델들과 비교했을 때, 모든 Task에서 성능이 매우 좋다.
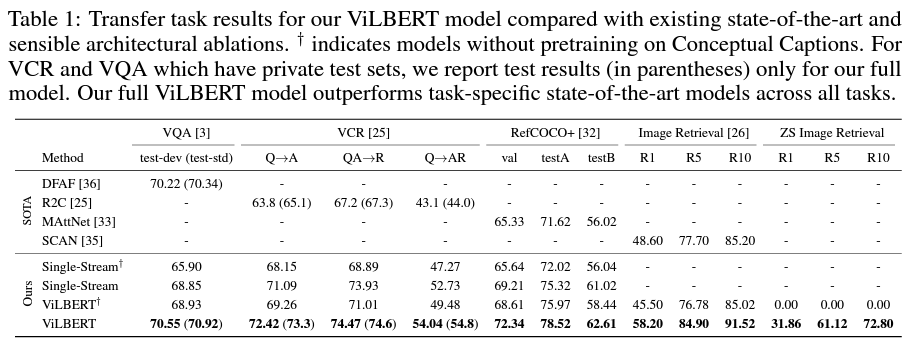
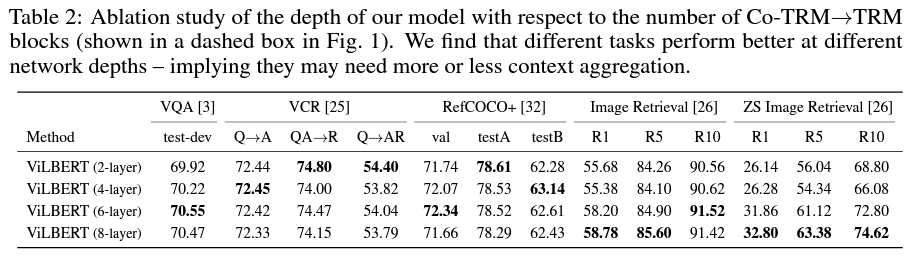
(2) Ablation study - layer의 depth에 따른 성능 비교 ⇒ Task마다 다르다.
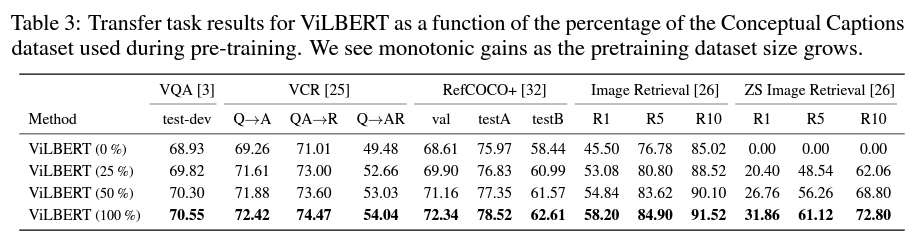
(3) Ablation study - dataset size에 따른 성능 비교 ⇒ (당연히) 사이즈가 클 수록 성능이 좋다.
나의 의견
논문을 선택한 이유
(1) 수업 시간에 다룬 논문 중에, 이 연구의 내용(vision과 sentence를 함께 인풋으로 사용했다는 것)이 참신하고 재미있게 느껴졌다.
읽고 난 후 의견
- Vision 분야는 관련 지식이 하나도 없었는데, Vision-and-Language 라는 토픽 덕분에 Vision에 대해 아주 짧은 지식이지만 알게되어 유익했다.
- 예를 들면 object detection을 한 것에 대한 IoU metric 같은 것,
NLP에서 tokenization방법이 여러개가 있듯이, 또는 임베딩 방법이 여러개가 있듯이 object detection 방법도 여러개가 있다는 것,
그리고 이것을 활용하여 이 연구에서는 디텍팅된 image feature를 트랜스포머 인풋으로 사용하는 것이 재미있었다. - Video의 경우 어떻게 object detecting된 것을 프레임단위로 끌고 가는지 궁금해서 추가 자료를 찾아봐야겠다.
- 이미지로 된 영상물도 마치 애니메이션처럼 연속된 프레임에서 하나의 object를 인지한다면 video to text와 연계하여 많은 태스크를 수행할 수 있을것 같다.



