Keyphrase Extraction을 위한 방법 중 unsupervised한 방식에서 주로 사용되었던 Phrase-Document-based 임베딩 비교하는 방식은, Phrase와 Document의 길이 차이로 인한 불안정성이 있었습니다.
이를 해결하기 위해 Document와 core-phrase를 마스킹한 Document의 임베딩을 비교한 MDERank 방법론을 소개하는 연구입니다.
읽은 날짜 2023.06.19
카테고리 #자연어처리논문리뷰, #Ranking, #InformationRetrieval
MDERank: A Masked Document Embedding Rank Approach for Unsupervised Keyphrase Extraction
- Authors: Linhan Zhang, Qian Chen, Wen Wang, Chong Deng, ShiLiang Zhang, Bing Li, Wei Wang, Xin Cao
- DOI: 10.18653/v1/2022.findings-acl.34
- Keywords:
- Issue Date: May 2022
- Publisher: ACL 2022
MDERank: A Masked Document Embedding Rank Approach for Unsupervised Keyphrase Extraction
Linhan Zhang, Qian Chen, Wen Wang, Chong Deng, ShiLiang Zhang, Bing Li, Wei Wang, Xin Cao. Findings of the Association for Computational Linguistics: ACL 2022. 2022.
aclanthology.org
ABSTRACT
(배경)
Keyphrase extraction (KPE)은 도큐먼트에서 핵심 콘텐츠에 대해 간결한 요약을 제공하는 phrase를 자동으로 추출하는 것으로, Information Retrieval 분야에서 다운스트림 태스크와 NLP 태스크를 수행하는데 유용하다.
(문제점)
이전의 SOTA 방법은 도큐먼트와 candidates의 representations의 similarity를 기반으로 candidate keyphrases를 선택하는 방식이었다.
이 방식은 긴 도큐먼트에서 퍼포먼스가 저하 (performance degradation) 되는 문제가 있었다. 왜냐하면 시퀸스의 길이가 달라서 도큐먼트와 keyphrase candidates의 representation 사이에 mismatch가 발생하여, 모순적인 상황이 발생하곤 했기 때문이다.
(RQ/목표)
기존의 embedding-based KPE approach에서의 문제를 해결하기 위하여, 새로운 접근법인 MDERank (Masked Document Embedding Rank)라는 novel unsupervised embedding-based KPE approac를 제안한다.
(방법)
MDERank는 mask strategy와 ranking candidates 를 활용하여 앞에서 언급한 문제를 해결한다.
Ranking candidates는 source document과 masked document 의 embedding간의 similarity 를 이용하여 계산된다.
나아가, novel self-supervised contrastive learning method를 제안하며, 이를 활용한 KPE-oriented BERT (KPEBERT) 모델을 개발했다. 이 모델은 Vanilla BERT보다 MDERank 에 더 호환성이 좋다.
(평가/의의)
6개의 KPE 벤치마크에서 테스트한 결과, MDERank는 SOTA unsupervised KPE approach보다 평균 1.80으로 성능이 좋았다. MDERank를 KPEBERT에 테스트할 경우, SOTA인 SIFRank에 비해 평균 3.53 만큼 성능이 좋다.
깃헙코드: Our code is available at https://github.com/LinhanZ/mderank.
1. 등장 배경
■ KPE (Keyphrase Extraction)
- Keyphrase Extraction을 위한 방법으로 candidates (후보 문장, 문단 들)과 기준 도큐먼트의 임베딩 거리를 측정하는 방식이 있다.
- 이 방식에서는 거리가 가까울 수록, candidate이 도큐먼트의 핵심 정보를 담고 있다고 보는데, candidates인 문장, 문단의 길이는 도큐먼트에 비해 짧기 때문에 제대로 결과가 나오지 않을 때가 있다.
■ 이 논문에서는
(1) Novel embedding-based unsupervised KPE approach (MDERank)
- 기존의 문제점을 해결하는 방법론으로 도큐먼트 간의 임베딩 거리를 비교하는 MDERank를 제안한다.
- 기준 도큐먼트와 비교할 대상으로는, candidates 부분을 마스킹한 도큐먼트이며, 임베딩 거리가 멀 수록 마스킹된 부분이 핵심 내용을 담고 있다고 간주할 수 있다.
(2) Novel self-supervised contrastive learning method 적용한 모델 KPEBERT
- MDERank와 호환성이 높은 KPE-oriented BERT (KPEBERT) 모델을 소개
(3) 여섯개의 다양한 KPE benchmark에 MDERank를 추가로 평가하고,
MDERank의 다양한 길이의 도큐먼트에서 robustness를 증명
2. 이론적 기반
(1) KPE (Keyphrase Extraction)
Keyphrase Extraction이란, 도큐먼트의 핵심 정보를 추출하는 것으며 supervised, unsupervised 접근 방법이 있다.
Supervised KPE (Keyphrase Extraction)
KPE를 sequence tagging 또는 sequence generation 태스크로 모델링한다.
단점: 대규모의 annotated data를 필요로 하는데, KPE annotations는 잘 없다는 것이 단점.
■ Sequence tagging
-
> Sahrawat et al., 2019
> Keyphrase Extraction from Scholarly Articles as Sequence Labeling using Contextualized Embeddings
> https://arxiv.org/abs/1910.08840
> Alzaidy et al., 2019
> Bi-LSTM-CRF Sequence Labeling for Keyphrase Extraction from Scholarly Documents
> https://dl.acm.org/doi/10.1145/3308558.3313642
> In The World Wide Web Conference, WWW 2019, ACM.
> Martinc et al., 2020
> TNT-KID: transformer-based neural tagger for keyword identification
> https://arxiv.org/abs/2003.09166
> Santosh et al., 2020
> SaSAKE: Syntax and Semantics Aware Keyphrase Extraction from Research Papers
> https://aclanthology.org/2020.coling-main.469/
> NikzadKhasmakhi et al., 2021
> Phraseformer: Multimodal Key-phrase Extraction using Transformer and Graph Embedding
> https://arxiv.org/abs/2106.04939
■ Sequence generation
-
> Liu et al., 2020
> Keyphrase Prediction With Pre-trained Language Model
> https://arxiv.org/abs/2004.10462
> Kulkarni et al., 2021
> Learning Rich Representation of Keyphrases from Text
> https://arxiv.org/abs/2112.08547
Unsupervised KPE (Keyphrase Extraction)
Unsupervised KPE 중에서 아래의 방법론들은 주로 산업계에서 주요 요소로 개발되었다. (industry deployment)
- TextRank (Mihalcea and Tarau, 2004)
- YAKE (Campos et al., 2018)
- EmbedRank (Bennani-Smires et al., 2018),
단점: 대규모의 annotated data를 필요로 하는데, KPE annotations는 잘 없다는 것이 단점.
■ Embedding-based approaches
- 대표적으로 EmbedRank (Bennani-Smires et al., 2018), SIFRank (Sun et al., 2020) 가 있다.
- 이 연구들은 SOTA performance를 내었다.
- 이런 방식들은 rule-based 방식으로 도큐먼트에서 keyphrase(KP)를 선택한 후, soring function을 이용해 candidates를 내림차순 정렬(decending order)하여, 가장 점수가 높은 candidates를 선택한다.
- Scoring function은 source document와 candidate의 임베딩간의 similarity를 계산하고,
- top-K 개의 candidates를 뽑아 최종 KPs로 선정한다.
=> 이 방식을 (이 연구의 연구진들은) Phrase-Document-based (PD) method)라고 한다.
> Bennani-Smires et al., 2018
> (EmbedRank) Keyphrase Prediction With Pre-trained Language Model
> https://aclanthology.org/K18-1022/
> Sun et al., 2020
> Sifrank: A new baseline for unsupervised keyphrase extraction based on pre-trained language model
> https://ieeexplore.ieee.org/document/8954611
■ Phrase-Document-based (PD) method
- 앞서 언급한, KPE의 Embedding-based approaches 에서 사용되는 주요 방법으로 PD method가 있다.
- 이 방법의 단점 (drawbacks):
(i) 도큐먼트는 candidates KPs 보다 대체적으로 매우 길기 때문에, 벡터 공간(latent semantic space)에서 similarities를 측정하는 것이 안정적이지 않다.
(ii) PD method의 KPs는 맥락 정보(contextual information) 없이 임베딩 계산 되기 때문에, 이에 따른 similarity에 한계가 있다.
3. 기존 연구와의 차별점
MDERank (Masked Document Embedding Rank)
- Novel unsupervised embedding-based KPE method
■ 기본 아이디어
- keyphrases는 도큐먼트의 semantics에서 중요한 역할을 하기 때문에, 이 keyphrase가 없으면 도큐먼트의 semantics에 큰 변화가 일어날 것이다.
■ 구현 아이디어 => Document-Document method
- 몇몇 Keyphrases를 마스킹 한 것과 original 도큐먼트와 임베딩 거리를 비교한다.
- 이 방법을 쓰면 similarity가 낮을 수록, 해당 keyphrase가 중요도를 가지게 된다. (increasing order)
■ 이 방법은 기존의 Phrase-Document method (PD) 의 두 가지 약점을 해결한다.
(1) original document와 masked document의 sequence length가 같으므로,
semantic space에서 이 둘의 similarities를 비교하는 것은 기존의 방식에 비해 의미있고 안정적임.
(2) masked document의 임베딩은 충분한 양의 context information을 바탕으로 계산되고,
이 contextual information은 BERT와 같은 contextualized representations model을 써서 진행되므로,
안정적으로 semantics를 포함할 수 있다.
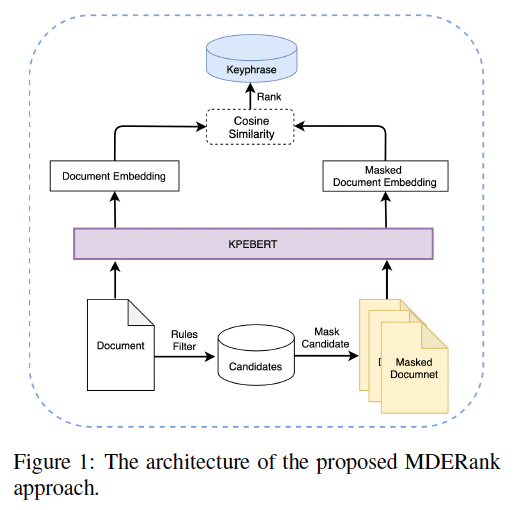
KPEBERT (Keyphrase Extraction BERT)
- Novel unsupervised embedding-based KPE method
- (Lewis et al., 2020; Zhang et al., 2020; Han et al., 2021) 의 연구에서 PLM(Pre-trained language model)에 최종 다운스트림 태스크에 가깝게 학습 시켜서 representations과 파인 튜닝 성능을 향상 시킨 것에 영감을 받아서, BERT모델에 novel self-supervised contrastive learning 을 하는 method (KPEBERT) 를 제안한다.
4. (모델/방법론) KPEBERT: KPE-oriented Self-supervised Learning
■ 아이템
설명
설명
4.1 Absolute Sampling
■ 아이템
설명
설명
4.2 Relative Sampling
■ 아이템
설명
설명
5. 실험 세팅, 실험 결과
설명
설명
5.1 Datasets and Metrics
■ 아이템
설명
설명
5.2 Baselines and Training Details
■ 아이템
설명
설명
5.3 Performance Comparison
■ 아이템
설명
설명
5.3 Analyses
■ 아이템
설명
설명
Effects of Document Length
■ 아이템
설명
설명
Effects of Encoder Layer and Pooling Methods
■ 아이템
설명
설명
6. CONCLUSION
- 중요한 결론 -
- 이론적 함의 -
- 실재적 함의 (practical implications) -
- Future work
- (1)
- (2)
나의 의견
논문을 선택한 이유
(1) 텍스트로 된 문서들을 효과적으로 분류하고, 비슷한 내용끼리 클러스터링을 할 방법에 대해 친구와 이야기를 나누던 중, MDERank 연구 논문이 재밌으니 읽어보라는 권유를 받았다.
(2) Abstract 및 Introduction 부분을 살펴보니 간단한 방법이지만 기발하고 효과적이라 생각되어, 연구 논문을 읽게 되었다,
읽고 난 후 의견
- Keyphrase Extraction이라고 하면 당연하게 candidates와 document를 비교하여 가장 최적의 내용을 찾거나, 도큐먼트를 summarization하여 keyphrase를 생성해야만 할 것 같다는 선입견이 있었다.
- 이 연구는 관점의 전환을 통해 기존의 문제점도 해결하고, 성능도 높인 똑똑한 연구라고 생각된다.



