LLM의 능력이 꽤 뛰어나다 보니, 이젠 LLM을 agent라는 존재로 부르는 학계 논문이나 과학 관련 기사가 많이 발견되고 있습니다.
LLM 스스로의 메모리 기반으로 계획 및 행동하고, 다양한 스킬(또는 Tool)을 활용할 수 있게 되었는데요,
이런 상황에서 LLM을 general purpose로 사용하는 경우도 있고, 또는 LLM에 퍼소나를 부여하여 그 전문적인 역할을 수행하게 하는 것에 대한 연구가 활발합니다.
퍼소나가 부여된 LLM을 조합하여 multi-agent의 상황을 조직하고, 인간의 개입없이 전문가 LLM간의 step-by-step 소통(시뮬레이션)을 통해 문제를 해결하는 것이 가능합니다.
이 논문은, Wikipedia와 같은 장문의 기사를 작성하는 과정에서 기사를 쓰기 전 단계(pre-writing stage)를 Writer와 Topic expert라는 두 LLM의 conversation simulating을 통해 해결하기 위한 시스템인 STORM(the Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking)에 대한 연구 내용입니다.
읽은 날짜 2024.04.28
카테고리 #LLM-Agent, #Multiagent, #Writing, #Sequential Decision-making, #Retrieve Information and Answer
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
- Authors: Yijia Shao Yucheng Jiang Theodore A. Kanell Peter Xu Omar Khattab Monica S. Lam (Stanford University)
- DOI:
- Keywords:
- Issue Date:
- Publisher: 저널이름이나 학회이름
ABSTRACT
배경 > 문제점 > 목표(RQ) > 방법 > 평가 > 결과 > 의의
배경:
우리는 Wikipedia와 견줄 수 있는 폭과 깊이를 가진, 근거 있고(grounded) 구조화된 긴 형식의 기사를 처음부터 작성하기 위하여 LLM적용하는 방법에 대한 연구를 한다.
문제점:
이 문제는 아직 탐구되지 않은 것으로, pre-writing stage부터 새로운 도전 과제들을 가지고 있다. 예를 들면, 토픽에 대해 어떻게 조사할 것인지, 글을 쓰기 전에 아웃라인을 어떻게 준비할 것인지와 같은 문제들이다.
목표: 우리는 STORM이라는 writing system을 소개한다. STORM은 (a writing system for ) Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking (검색 및 다관점에서 질문을 통해 토픽의 아웃라인을 종합하는 글쓰기 시스템) 을 뜻한다.
방법:
STORM은 (1)주어진 토픽을 조사하기 위한 다양한 관점을 발굴하고, (2) 다양한 관점을 가지고 있는 writer가 믿을 수 있는 인터넷 출처를 바탕으로 한 토픽 전문가에게 질문하는 것에 대한 대화를 시뮬레이션하고, (3) 수집한 정보를 큐레이팅하여 아웃라인을 생성한다.
평가: 평가를 위해 우리는 FreshWiki라는 데이터셋을 선별했다. (이 데이터셋은 최신의 하이 퀄리티 Wikipedia articles 데이터셋이다.)
그리고 pre-writing stage를 평가하기 위하여 outline assessments를 공식화(formulate)했다.
더 나아가, 우리는 경험있는 Wikipedia editors로 부터 피드백을 수집했다.
결과:
아웃라인을 기반으로 검색-증강된(outline-driven retrieval-augmented baseline) 베이스라인으로 생성된 기사와 비교하여,
STORM의 기사들은 좀 더 조직화 되어있고(25% 증가), 더 넓은 coverage를 가졌다(10%).
또한 전문가들의 피드백은 근거있는 긴 기사(grounded long articles)를 생성하기 위한 새로운 도전 과제들을 식별하는데 도움이 되었다. 예를 들면, 출처의 bias가 기사에 전달된다거나, 관련성이 없는 사실에 대해 과하게 연결짓는 것과 같은 이슈들이다.
1. INTRODUCTION
■ Expository writing을 돕기 위해서는 section expanding보다는 pre-writing stage를 자동화 하는 것이 도움이 된다.
LLM은 인상적인 writing 능력을 보여주고 있다. 하지만 LLM을 사용하여 Wikipedia페이지와 같이 근거가 있고 긴 형식의 기사를 어떻게 작성하도록할 수 있는가에 대한 것은 아직 명확하지 않다.
독자에게 토픽에 대해 조직화된 방법으로 정보를 제공하는 것과 같은 expository writing은 pre-writing stage에서 철저한 조사와 준비( research and planning) 을 필요로 한다.
Wikipedia 기사 작성에 대한 이전의 연구들은 일반적으로 pre-writing stage를 건너뛰었다.
예1) Liu et al.(2018) - reference document가 사전에 제공되었다고 가정.
예2) Fan and Gardent(2022) - article outline은 제공된다고 가정하고 각 section을 자세히 작성하는 것에 집중.
이러한 가정은 일반적인 상황에서는 적용되지 않는데, 왜냐하면 참고자료를 모으고 outline을 작성하는 것은 (외부 정보 소스,에서 자료를 식별하고 평가하고 조직화 하는 것과 같은) advanced informatio literacy skills를 요구하고, 이것은 숙련된 writers에게도 도전적인 태스크이기 때문이다.
이 과정을 자동화 하는 것인 개인들이 토픽에 대해 깊게 공부하는 것을 시작하는데 도움이 되고, expository writing에서 전문가들의 시간을 크게 줄여줄 수 있다.
■ 이 논문에서 장문의 기사를 작성하기 위해 정의한 두 가지 태스크
이런 도전과제를 탐구하기 위해, 우리는 Wikipedia-like articles를 처음부터(from scratch) 어떻게 작성하는가에 대해 집중했다.
일반적인 human writing process (phases of pre-writing, drafting, and revising)를 참고하여 (Rohman, 1965; Munoz-Luna, 2015),
이 문제를 두 가지 태스크로 분해했다.
- 첫번째 태스크 - (to conduct research to generate an outline.)
outline을 생성하기 위해 조사를 하는 태스크.
예) multi-level sections의 리스트 생성, 일련의 reference documents들을 수집하는 것. - 두번째 태스크 - (uses the outline and the reference to produce the full-length article.)
첫번째 태스크의 결과물인 outline과 reference를 이용하여, 전체 길이의 article을 생성하는 것.
PLM(Pre-trained language model)은 본질적으로 풍부한 지식을 보유하고 있기 때문에,
직접적인 접근 방식으로는 LLM의 parametric knowledge에 의존하여 outline 또는 전체 article를 생성하는 것이다(Direct Gen).
하지만, 이런 접근 방식은 디테일이 부족하고, 할루시네이션이 발생한다는 한계가 있다(Xu et al., 2023),
특히 long-tail topics를 다룰 때 이러한 문제가 더 드러난다(Kandpal et al., 2023).
그렇기때문에 외부 소스(external sources)를 활용하는 것이 중요하고,
현재 사용되는 전략들은 종종 RAG(Retrieval-augmented generation)을 포함한다.
왜냐면, 간단한 topic search를 통해서는 많은 정보가 나타나지 않기 때문에, pre-writing stage에서 RAG을 통해 topic에 대해 조사한다.
*long-tail topics란? (출처: ChatGPT 4)
일반적으로 인터넷 검색, 마케팅, 그리고 정보 검색에서 사용되는 용어로 상대적으로 검색 빈도가 낮지만 구체적이고 특정한 정보를 지칭한다.
- 예: '커피' 라는 검색어는 일반적이고 높은 검색량을 가짐.
'에티오피아 샤키소 농장의 워시드 커피 원두' 와 같은 검색어의 경우, 훨씬 구체적이고 검색 빈도는 낮지만 특정한 관심사나 필요를 충족 시킴.
■ 이 연구에서 제안하는 STORM
instruction-tuned models는 직접적으로 questions를 생성하도록 프롬프팅될 수 있지만,
이를 통해 생성된 질문은 전형적으로 "What", 'When", "Where" 과 같은 기본적인 질문들이었다.
(Figure 1의 (A) Direct Prompting 참고)
LLM에 더 나은 research 능력을 부여하기 위해, 우리는 STORM paradigm을 제안한다.
STORM은 토픽 검색과 다양한 관점의 질문을 통해 Topic outlines를 종합하는(the Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking) 것이다.

■ STORM 설계를 위한 두가지 가설(hypotheses)
- 첫번째 가설: diverse perspectives lead to varied questions.
다양한 관점들은 여러 다른 질문들을 낳는다. - 두번째 가설: formulating in-depth quesitons requires iterative research.
심층적인 질문을 만들어내기 위해서는 반복적인 리서치를 필요로 한다.
이 두가지 가설을 바탕으로, STORM은 novel multi-stage approach를 차용한다.
(1) 비슷한 토픽에 대한 Wikipedia articles를 검색하고 분석하여, 다양한 관점(diverse perspectives)을 발견한다.
(2) Questin asking을 위하여, 특정 관점(specific perspectives)으로 LLM을 의인화/구체화(personifies)한다.
(Figure 1의 (B) Perspective-Guided Question Asking 참고)
(3) 반복적인 리서치를 통해 follow-up questions를 고도화한다.
(Figure 1의 (C) Conversational Question Asking 참고)
- STORM은 생성된 questions에 대한 answers가 Internet을 기반으로 하도록 하는, multi-turn conversations를 시뮬레이션한다.
(4) LLM 내부 지식과 수집된 정보를 기반으로, STORM은 outline을 생성한다.
이 outline의 sectrion들을 확장하여 작성하면 Wikipedia-like article로 발전할 수 있다.
■ STORM의 평가
(1) 데이터셋
FreshWiki 데이터셋을 만들고, 이를 이용해 STORM을 평가했다.
FreshWiki 데이터셋은 최신의 high-quality Wikipedia articles를 선정한 것으로,
pre-training 과정에서 데이터 유출(data leakage)을 방지할 수 있다.
(2) 평가 메트릭
pre-writing stage에 대한 연구를 수행하기 위하여, human-written articles 대비 STORM의 outline 품질을 평가하기 위한 metrics을 정의했다.
(3) 전문가 평가(expert evaluation)
숙련된 Wikipedia editors 그룹을 초대하여 전문가 평가를 수행했다.
에디터들은 STORM이 특히 articles의 너비(breadth)와 구조화(organization) 관련하여 outline-driven RAG baseline을 뛰어넘는다고 평가했다.
또한, 에디터들은 다음과 같은 문제 제기를 통해 후속 연구에 대한 도전 과제를 식별했다.
- Internet의 bias가 생성되는 기사에 영향을 미침. (the bias on the Internet affects the generated articles.)
- LLMs이 관련성이 낮은 사실들에 대해 잘못 연결지음. (LLMs fabricate connections between unrelated facts.)
■ 우리의 연구는 다음과 같은 주요 기여(contributions)를 포함한다.
- LLM 시스템이 장문의 근거있는 기사를 생성하는 것에 대한 가능성을 평가하고,
특히 pre-writing challenges에서 outline과 최종 기사의 품질을 평가하기 위하여,
FreshWiki 데이터셋을 선별하고 평가 기준(evaluation criteria)을 수립하였다.
To evaluate the capacity of LLM systems at generating long-form grounded articles from scratch, and the pre-writing challenge in particular, we curate the FreshWiki dataset and establish evaluation criteria for both outline and final article quality. - pre-writing stage를 자동화하는 새로운 시스템인 STORM을 제한한다.
STORM은 LLMs를 사용해 예리한(incisive) 질문을 하고, Internet에서 믿을 수 있는 정보를 검색하는 방법으로
토픽을 리서치하고 outline을 생성한다.
We propose STORM, a novel system that automates the pre-writing stage. STORM researches the topic and creates an outline by using LLMs to ask incisive questions and retrieving trusted information from the Internet. - 자동 평가와 인적 평가(human evaluation) 모두 우리 접근법의 효율성을 입증한다.
전문가 피드백은 근거있는 장문의 기사를 생성하기 위한 새로운 도전 과제를 추가로 보여준다.
Both automatic and human evaluation demonstrate the effectiveness of our approach. Expert feedback further reveals new challenges in generating grounded long-form articles.
2. FreshWiki
-
-
2.1 The FreshWiki Dataset
■ 아이템
설명
설명
2.2 Outline Creation and Evaluation
■ 아이템
설명
설명
3. Method
STORM은 pre-writing stage를 자동화 하기 위하여,
effective question asking(3.1, 3.2)을 통해 주어진 토픽에 대해 리서치하고,
creating an outline(3.3)을 하는 과정을 거친다.
outline은 수집된 references를 바탕으로 full-length로 확장된다. (3.4)
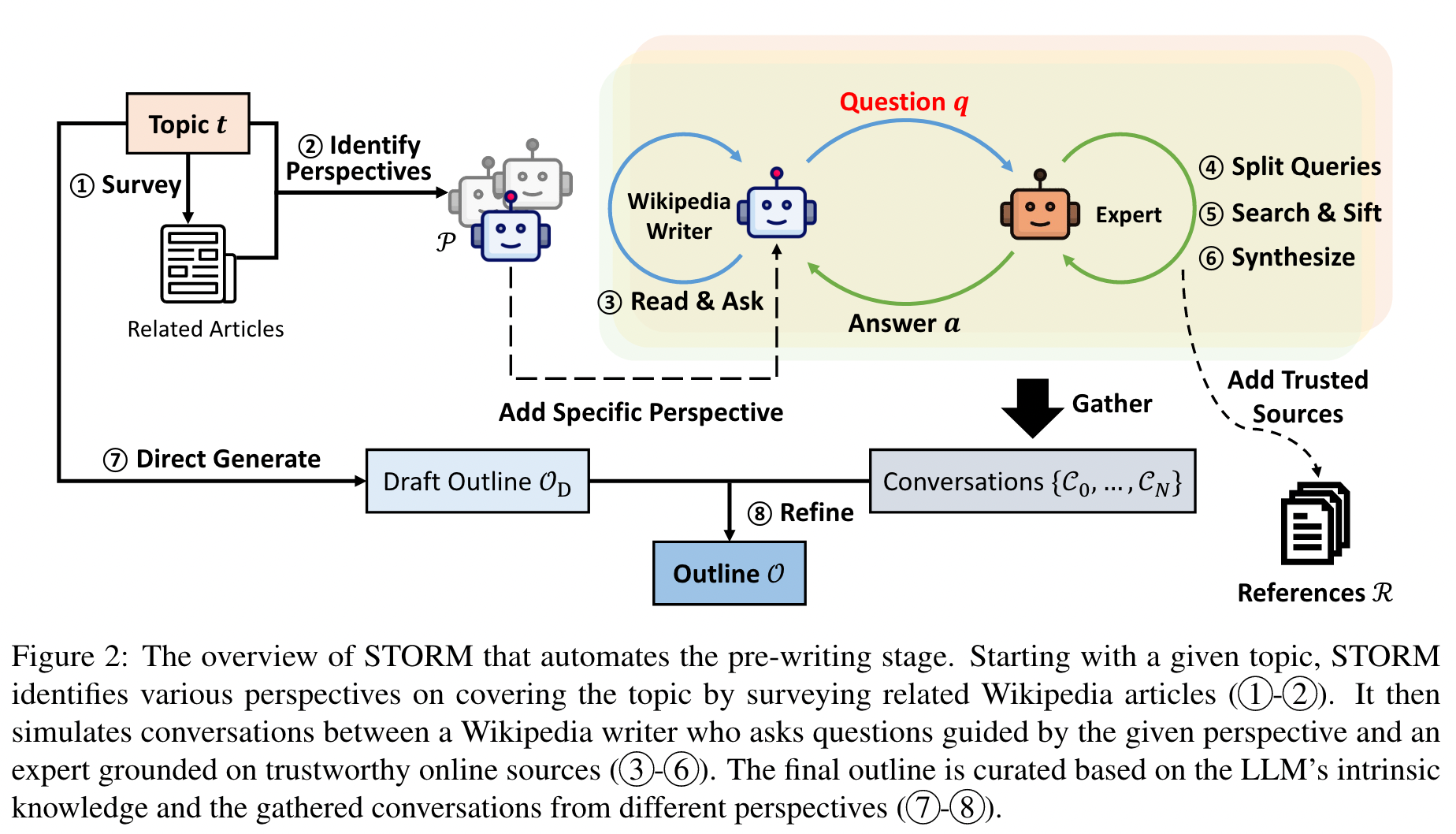
3.1 Perspective-Guided Question Asking
■ 토픽 t에 대한 perspectives P = {p0(=basic information), p1, p2, ... , pN}
*stakeholder theory in business: diverse stakeholders는 varying facets of a company를 우선순위로 둔다.
동일한 토픽에 대해 리서치하더라도, 개인의 다양한 관점(distinct perspectives)에 따라 각각 다른 aspects에 주목할 수 있고, multifacted information을 발견할 수 있다.
또한, 특정 관점(perspectives)은 사전 지식으로 활용되어, 개인들이 더 심층적인 질문을 하도록 이끌 수 있다.
예를 들어, event planner는 '2022년 겨울 올림픽 오프닝 세레모니' 라는 주제에 대해 '교통편 마련', '예산'과 같은 질문을 할 수 있고, 동일 주제에 대해 'a layperson'은 행사의 기본적인 정보에 대한 일반적인 질문을 할 수있다. (Figure 1 (A) )
주어진 input topic t에 대하여 STORM은 비슷한 토픽들로부터 이미 존재하는 articles를 surveying함으로ㅓ써 다른 관점(perspectives)들을 탐구한다. 그리고 이러한 perspectives들을 question asking processing을 컨트롤 하는데 사용한다.
(Figure 1의 (A) )
특히 STORM은 LLM에 a list of related topics를 생성하도록 프롬프트하고,
Wikipedia API를 통해 해당 articles를 얻을 수 있다면, 이 Wikipedia articles에서 목차(table of contents)를 추출하도록 한다.
(Figure 2의 1 )
이러한 목차는 LLM이 N개의 perspectives인 P = {p1, p2, ... , pN} 에 대한 컨텍스트를 만들어내는 것에 집중된다.
P는 토픽 t에 대한 종합적인 기사(comprehensive article)을 위해 선별적으로 사용된다.
토픽 t에 대한 기본적인 정보가 확실히 포함되도록, P에 p0 = "basic fact writer focusing on broadly covering the basic facts about the topic" 을 추가했다. 즉, P = {p0, p1, p2, ... , pN}.
각 perspective인 p를 활용해서 LLM이 병렬적으로 question asking 프로세스를 수행하도록 한다.
3.2 Simulating Conversations
■ 아이템
설명
설명
3.3 Creating the Article Outline
■ 아이템
설명
설명
3.4 Writing the Full-Length Article
■ 아이템
설명
설명
4. Experiments
■ 아이템
설명
설명
4.1 Article Selection
■ 아이템
설명
설명
4.2 Automatic Metrics
■ 아이템
설명
설명
4.3 Baselines
■ 아이템
설명
설명
4.4 STORM Implementation
■ 아이템
설명
설명
5. Results and Analysis
5.1 MainResults
■ 아이템
설명
설명
5.2 Ablation Studies
■ 아이템
설명
설명
6. Human Evaluation
■ 아이템
설명
설명
(1) Articles produced by STORM exhibit greater breadth and depth than oRAG outputs.
■ 아이템
설명
설명
(2) More information in |R| poses challenges beyond factual hallucination.
■ 아이템
설명
설명
(3) Generated articles trail behind well-revised human works.
■ 아이템
설명
설명
(4) Generated articles are a good starting point.
■ 아이템
설명
설명
7. Related Works
■ 아이템
설명
설명
Retrieval-Augmented Generation (RAG)
■ 아이템
설명
설명
Automatic Expository Writing
■ 아이템
설명
설명
Question Asking in NLP
■ 아이템
설명
설명
8. CONCLUSION
- 중요한 결론 -
- 이론적 함의 -
- 실재적 함의 (practical implications) -
- Future work
- (1)
- (2)
Limitations
■ 아이템
설명
설명
Ethics Statement
■ 아이템
설명
설명
나의 의견
논문을 선택한 이유
(1) 이유1
(2) 이유2
읽고 난 후 의견
- 의견1
- 의견2
'논문 리뷰 > HCI 논문 리뷰' 카테고리의 다른 글
| Reuters Institute Digital News Report (0) | 2023.11.28 |
|---|---|
| [시각화] survey on visualization for scientific literature topics (1) | 2023.10.15 |
| [시각화] Visualization Techniques for Topic Model Checking (1) | 2023.10.13 |
| [HCI] (IUI'18) Burst Your Bubble! An Intelligent System for Improving Awareness of Diverse Social Opinions (0) | 2023.09.20 |
| [Journalism] (2005) News framing: Theory and typology (0) | 2023.09.08 |



